
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- opencv
- Python
- ADP
- LDA
- ADsP
- 데이터분석준전문가
- 워드클라우드
- pandas
- iloc
- 독립표본
- dataframe
- 텍스트분석
- numpy
- 데이터불균형
- DBSCAN
- datascience
- 빅데이터분석기사
- PCA
- 크롤링
- 데이터분석전문가
- 대응표본
- 파이썬
- 군집화
- t-test
- 언더샘플링
- 빅데이터
- Lambda
- 주성분분석
- 데이터분석
- 오버샘플링
Archives
Data Science LAB
[Python] 일원 분산 분석(ANOVA) 본문
728x90
분산분석
- 두 개 이상의 집단에서 그룹 평균 간 차이를 그룹 내 변동에 비교하여 살펴보는 통계 분석 기법
- 두 개 이상의 집단의 평균 차이에 대한 통계적 유의성 검정
일원 배치 분산 분석
- 분산분석에서 반응값에 대한 하나의 범주형 변수의 영향을 알아보기 위해 사용됨
- 모집단의 수에는 제한이 없으며, 표본의 수는 같지 않아도 됨
- F 검정 통계량 사용
- 각 집단의 측정치는 독립적이며, 정규분포를 따라야 함
- 각 집단 측정치의 분산은 같다고 가정(등분산성)
| 요인 | 제곱합(SS) | 자유도(df) | 평균제곱(MS) | 분산비(F) |
| 처리 | SSA | k-1 | MSA | F = MSA/MSE |
| 오차 | SSE | N-k | MSE | |
| 전체 | SST | N-1 |
귀무가설(H0) : k개의 집단 간 모평균에는 차이가 없다.
대립가설(H1) : k개의 집단 간 모평균이 모두 같다고는 할 수 없다.
사후 검정
분산분석 결과 귀무가설이 기각되어 적어도 한 집단에서 평균에 차이가 있다는 것이 통계적으로 증명된 경우, 어떤 집단들에 대해 평균의 차이가 존재하는 지를 알아보기 위해 실시하는 분석
- 던칸의 MRT, 피셔의 최소유의차(LSD), 튜키의 HSD, Scheffe 등등
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
import statsmodels.api as sm
from statsmodels.stats.anova import AnovaRM
from scipy import stats
group_list = ['a','b','c']
subs_list = ['01','02','03','04','05','06','07','08','09','10']
df_1way = pd.DataFrame(columns = ['group','my_value'])
my_row = 0
for ind_g, group in enumerate(group_list):
for sub in subs_list:
my_val = np.random.normal(ind_g,1,1)[0]
df_1way.loc[my_row] = [group,my_val]
my_row = my_row+1
my_model = smf.ols(formula = 'my_value ~ group',data = df_1way)
my_model_fit = my_model.fit()
anova = sm.stats.anova_lm(my_model_fit,typ=2)
print(anova)
scipy stats 활용
stats.f_oneway(df_1way[df_1way['group'] == 'a'].my_value, df_1way[df_1way['group'] == 'b'].my_value,df_1way[df_1way['group'] == 'c'].my_value)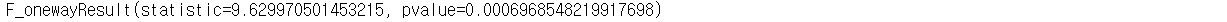
정규성 검정 실패시 -> kruskal test
from scipy import stats
x = [1,3,5,7,9]
y = [2,4,6,8,10]
stats.kruskal(x,y)
728x90
'🛠 Machine Learning > 기초 통계' 카테고리의 다른 글
| [Python] 선형 회귀분석 (0) | 2022.08.22 |
|---|---|
| [Python] 교차 분석 (카이제곱 검정) (0) | 2022.08.21 |
| [Python] 이원 배치 분산 분석 (Two-way ANOVA) (0) | 2022.08.20 |
| [Python] 독립 / 대응 표본 t 검정 (0) | 2022.03.15 |
| [Python] 기술 통계 (0) | 2022.03.13 |
'🛠 Machine Learning/기초 통계' Related Articles
more



Comments