
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- ADsP
- t-test
- ADP
- PCA
- iloc
- 대응표본
- 데이터분석전문가
- 텍스트분석
- opencv
- 데이터불균형
- DBSCAN
- 빅데이터분석기사
- datascience
- LDA
- 오버샘플링
- 크롤링
- 독립표본
- 워드클라우드
- 주성분분석
- 군집화
- 언더샘플링
- 빅데이터
- Python
- pandas
- 파이썬
- dataframe
- 데이터분석준전문가
- numpy
- Lambda
- 데이터분석
Data Science LAB
[Python] 평균 이동 본문
Mean Shift
평균 이동(Mean Shift)은 KMeans와 유사하게 중심을 군집의 중심으로 지속적으로 움직이면서 군집화를 수행한다.
KMeans는 중심에 소속된 데이터의 평균 거리 중심으로 이동하지만, 평균 이동은 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동시킨다.
평균 이동 군집화는 데이터의 분포도를 이용하여 군집의 중심점을 찾는다. 군집 중심점은 데이터 포인트가 모여 있는 곳이라는 생각에서 착안한 것이며 이를 위해 확률 밀도 함수를 이용한다. 일반적으로 주어진 모델의 확률 밀도 함수를 찾기 위해 KDE(Kernel Density Estimation)를 이용한다. 특정 데이터 반경 내의 데이터 분포 확률 밀도가 가장 높은 곳으로 이동하기 위해서 주변 데이터와의 거리 값을 KDE 함수의 입력 값으로 입력한 뒤 반환 값을 현재 위치에서 업데이트하면서 이동한다. 이러한 방식을 전체 데이터에 반복적으로 적용하여 데이터 군집의 중심점을 찾아낸다.
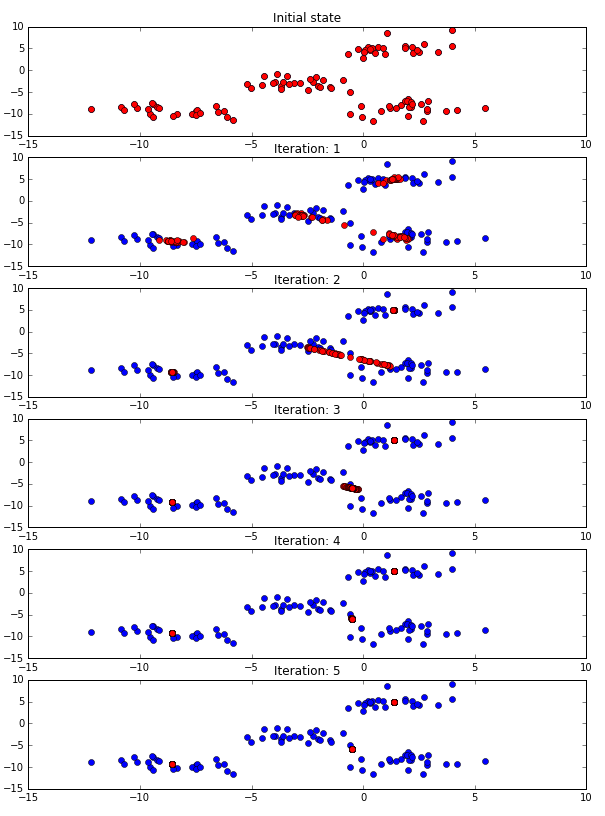
1. 개별 데이터의 특정 반경 내의 주변 데이터를 포함한 데이터 분포도를 KDE 기반의 MeanShift 알고리즘으로 계산
2. KDE로 계산된 데이터 분포도가 높은 방향으로 데이터 이동
3. 모든 데이터들이 1~2까지 수행하면서 데이터 이동. 개별 데이터들이 군집 중심점으로 모임
4. 지정된 반복 횟수만큼 전체 데이터에 대해 KDE 기반으로 데이터를 이동시키면서 군집화 수행
5. 개별 데이터들이 모인 중심점을 군집 중심점으로 설정
KDE는 커널 함수를 통해 어떤 변수의 확률 밀도 함수를 추정하는 대표적 방법으로, 관측된 데이터 각각에 커널 함수를 적용한 값을 모두 더한 뒤 데이터 건수로 나눠 확률 밀도 함수 추정한다. 대표적인 커널 함수로 가우시안 분포 함수가 사용된다. 또한, 대역폭 h에 따라 확률 밀도 추정 성능을 크게 좌우할 수 있다. 작은 h값은 좁고 뾰족한 KDE를 가지게 되며, 이것은 변동성이 매우 크며 과적합 하기 쉽다. 너무 큰 h값은 과도하게 평활화된 KDE로 인하여 과소적합하기 쉽다. 따라서 적절한 KDE 대역폭 h를 결정하여야 한다.
알고리즘 적용 예제
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import MeanShift
X,y = make_blobs(n_samples=200,n_features=2,centers=3,cluster_std=0.7,random_state=0)
meanshift = MeanShift(bandwidth = 0.8)
cluster_labels = meanshift.fit_predict(X)
print("cluster 유형 : ",np.unique(cluster_labels))
표준편차를 0.7로 설정한 3개의 군집 데이터에 대해 bandwidth를 0.8로 설정한 평균 이동 군집화 알고리즘을 적용한 예제를 생성하였다.
생성된 군집은 0-5로 6개이며 지나치게 세분화되어 군집화되었다.
bandwidth를 작게할수록 군집 개수가 많아짐
=> bandwidth를 높여야 함
bandwidth를 1로 조정
meanshift = MeanShift(bandwidth = 1)
cluster_labels = meanshift.fit_predict(X)
print("cluster 유형 : ",np.unique(cluster_labels))
3개의 군집으로 잘 분류된 것을 확인하였다.
최적화된 bandwidth찾기
from sklearn.cluster import estimate_bandwidth
bandwidth = estimate_bandwidth(X)
print('bandwidth 값 : ',round(bandwidth,3))
사이킷런에서 제공하는 estimate_bandwidth()를 사용하면 최적의 bandwidth값을 찾을 수 있다.
최적화된 bandwidth값 적용
import pandas as pd
clusterDF = pd.DataFrame(data=X,columns = ['ftr1','ftr2'])
clusterDF['target'] = y
#estimate_bandwidth()로 최적의 bandwidth 계산
best_bandwidth = estimate_bandwidth(X)
meanshift = MeanShift(bandwidth = best_bandwidth)
cluster_labels = meanshift.fit_predict(X)
print("cluster labels 유형 : ",np.unique(cluster_labels))
최적의 bandwidth를 적용하여 군집화 모델 생성 결과 3개의 군집으로 분류되었다.
군집 시각화
import matplotlib.pyplot as plt
%matplotlib inline
clusterDF['meanshift_label'] = cluster_labels
centers = meanshift.cluster_centers_
unique_lables = np.unique(cluster_labels)
markers = ['o','s','^','x','*']
for label in unique_lables:
label_cluster = clusterDF[clusterDF['meanshift_label'] == label]
center_x_y = centers[label]
#군집별로 다른 마커로 산점도 적용
plt.scatter(x=label_cluster['ftr1'],y=label_cluster['ftr2'],edgecolor='k',marker=markers[label])
#군집별 중심표현
plt.scatter(x=center_x_y[0],y = center_x_y[1], s = 200, color = 'gray',alpha=0.9,marker=markers[label])
plt.scatter(x=center_x_y[0],y=center_x_y[1],s=70,color='k',marker='$%d$' % label)
plt.show()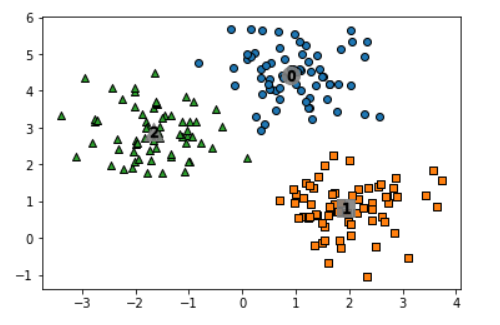
target값과 군집 label 비교
print(clusterDF.groupby('target')['meanshift_label'].value_counts())
target값과 label값이 잘 매칭된 것을 확인
평균이동은 데이터셋의 형태를 특정 형태로 가정하거나 특정 분포도 기반의 모델로 가정하지 않아 유연한 군집화가 가능하다. 또한 이상치의 영향력도 크지 않으며 미리 군집의 수를 지정하지 않아도 되기 때문에 이미지나 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 데에 뛰어난 역할을 수행한다.
###참고
http://www.chioka.in/meanshift-algorithm-for-the-rest-of-us-python/
Meanshift Algorithm for the Rest of Us (Python)
What is Meanshift? Meanshift is a clustering algorithm that assigns the datapoints to the clusters iteratively by shifting points towards the mode. The mode can be understood as the highest density of datapoints (in the region, in the context of the Meansh
www.chioka.in
'🛠 Machine Learning > Clustering' 카테고리의 다른 글
| [Python] DBSCAN (0) | 2022.03.04 |
|---|---|
| [python] GMM(Gaussian Mixture Model) (0) | 2022.03.03 |
| [Python] 군집 평가(실루엣 계수) (0) | 2022.03.01 |
| [Python] KMeans Clustering(K-평균 군집화) (0) | 2022.02.28 |



