
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 데이터분석전문가
- 빅데이터분석기사
- 주성분분석
- ADP
- Lambda
- datascience
- 군집화
- iloc
- 파이썬
- 독립표본
- 언더샘플링
- 데이터불균형
- PCA
- 워드클라우드
- numpy
- opencv
- 크롤링
- 데이터분석
- 빅데이터
- LDA
- ADsP
- 대응표본
- DBSCAN
- dataframe
- 데이터분석준전문가
- pandas
- 오버샘플링
- 텍스트분석
- t-test
- Python
Archives
Data Science LAB
[Python] 데이터 에듀 ADP 실기 모의고사 3회 3번 파이썬 ver. (비정형 데이터마이닝) 본문
728x90
사용 데이터 : 공구 블로그 댓글.txt, 사전.txt
1. '공구 블로그 댓글.txt' 파일을 읽어 들여 숫자, 특수 문자 등을 제거하는 전처리 작업을 시행하시오.
import pandas as pd
import numpy as np
f = open('../data/공구 블로그 댓글.txt', 'r')
data = f.read()
data
import re
text = re.sub('[^A-Za-z가-힣\\s]',' ',data)
text
2. '사전.txt'를 사전에 추가하고 문서에서 형용사를 추출하라
f = open('../data/사전.txt', 'r')
dictionary = f.read()
dictionary
from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
hannanum.morphs(text)
# 부착되는 품사 태그의 기호와 의미 확인
okt.tagset
kkma.tagset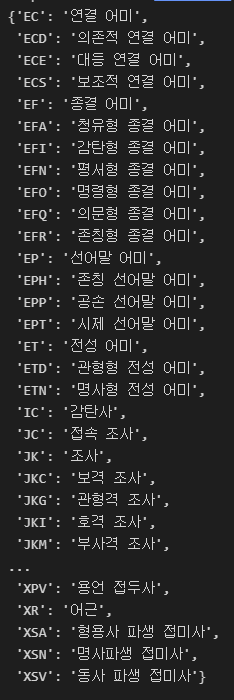
word = okt.pos(text)
word = pd.DataFrame(word, columns=['term', 'pos'])
word.head()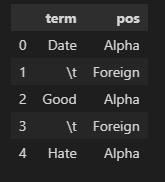
adj = []
for i in range(len(word)):
if word['pos'][i] == 'Adjective':
adj.append(word['term'][i])
else:
continue
adj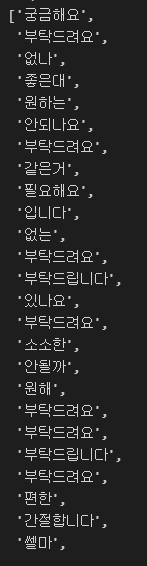
형용사만 데이터프레임에 추가
3. 2월에 게시된 댓글의 명사를 추출하고 빈도수를 시각화하시오.
import pandas as pd
df = pd.read_table('../data/공구 블로그 댓글.txt', sep='\t', engine='python', encoding='euc-kr')
df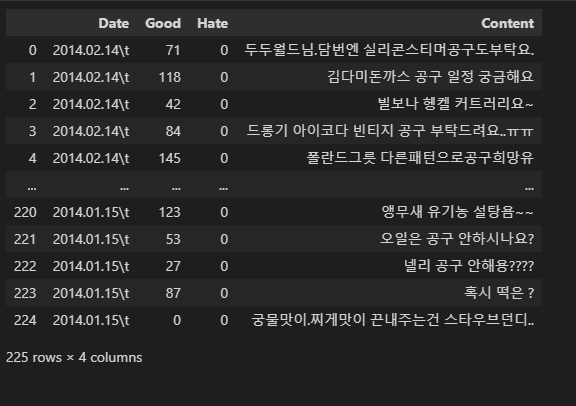
df['Date'] = pd.to_datetime(df['Date'])
df = df[df['Date'].dt.month == 2]
df
content = df['Content'].values.astype('str')
text = ' '.join(s for s in content)
textcontent를 하나의 텍스트(문단)으로 연결해줌
text = re.sub('[^A-Za-z가-힣\\s]',' ',text)
text
from collections import Counter
okt = Okt()
nouns = okt.nouns(text)
count_dict = Counter(nouns)
top10 = pd.DataFrame({'terms':count_dict.keys(), 'freq':count_dict.values()}).sort_values(by='freq', ascending=False).iloc[:10,]
top10 = top10.set_index('terms').sort_values(by='freq', ascending=False)
top10
명사를 추출하여 상위 10개의 단어만을 데이터프레임 형식으로 저장
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#matplotlib 패키지 한글 폰트 설정 시작
plt.rcParams["font.family"] = 'Malgun Gothic'
plt.rcParams['figure.figsize'] = (10,6)
plt.rcParams['font.size'] = 16
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots(1,1)
plt.title("2월 댓글 빈출 명사")
top10.plot.bar(ax = ax,rot=45)
plt.show()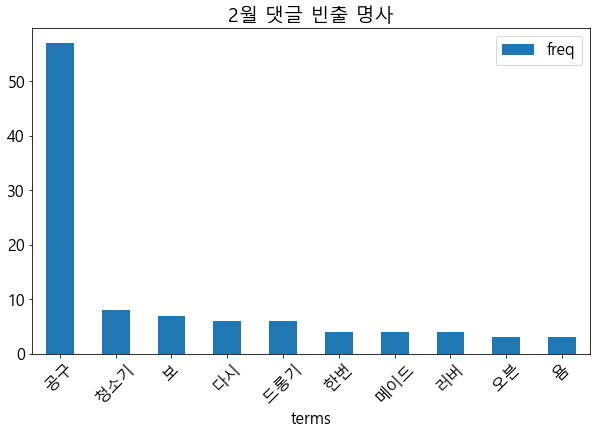
728x90
'adp 실기 > 기출문제' 카테고리의 다른 글
| [Python] 데이터 에듀 ADP 실기 모의고사 4회 2번 파이썬 ver. (통계분석) (0) | 2022.09.10 |
|---|---|
| [Python] 데이터 에듀 ADP 실기 모의고사 파이썬 ver. (정형 데이터마이닝) (0) | 2022.09.08 |
| [Python] 데이터 에듀 ADP 실기 모의고사 3회 2번 파이썬 ver. (정형데이터마이닝) (0) | 2022.09.06 |
| [Python] 데이터 에듀 ADP 실기 모의고사 3회 1번 파이썬 ver. (통계 분석) (0) | 2022.09.05 |
| [Python] 데이터 에듀 ADP 실기 모의고사 2회 3번 파이썬 ver. (비정형 데이터마이닝) (0) | 2022.09.04 |
'adp 실기/기출문제' Related Articles
more




Comments