
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- dataframe
- 언더샘플링
- pandas
- ADsP
- 크롤링
- DBSCAN
- t-test
- 빅데이터
- ADP
- 데이터분석
- 빅데이터분석기사
- 오버샘플링
- LDA
- datascience
- 독립표본
- Python
- 주성분분석
- 데이터불균형
- 군집화
- iloc
- opencv
- 데이터분석준전문가
- Lambda
- numpy
- 워드클라우드
- PCA
- 텍스트분석
- 대응표본
- 파이썬
- 데이터분석전문가
Archives
Data Science LAB
[Python] 데이터 에듀 ADP 실기 모의고사 파이썬 ver. (정형 데이터마이닝) 본문
728x90
사용 데이터 : weatherAUS.csv
| 변수 | 데이터 형태 | 설명 |
| Date | 날짜형 | 날짜 |
| Location | 범주형 | 장소 |
| MinTemp | 수치형 | 최저 온도 (섭씨) |
| MaxTemp | 수치형 | 최고 온도 (섭씨) |
| Rainfall | 수치형 | 하루 동안 기록된 강우량 |
| WindGustDir | 범주형 | 자정까지 24시간 동안 가장 강한 바람이 부는 방향 |
| WIndGustSpeed | 수치형 | 24시간에서 자정 사이 가장 강한 바람 속도 (km/h) |
| WindDir9am | 범주형 | 바람 방향 |
| WindDIr3pm | 범주형 | 바람 방향 |
| WindSpeed9am | 수치형 | 평균 10분 이상 풍속 |
| WindSpeed3pm | 수치형 | 평균 10분 이상 풍속 |
| Humidity9am | 수치형 | 습도 |
| Humidity3pm | 수치형 | 습도 |
| Pressure9am | 수치형 | 대기압 |
| Pressure3pm | 수치형 | 대기압 |
| Cloud9am | 범주형 | 구름으로 하늘이 가려진 정도 |
| Cloud3pm | 범주형 | 구름으로 하늘이 가려진 정도 |
| Temp9am | 수치형 | 온도 |
| Temp3pm | 수치형 | 온도 |
| RainToday | 범주형 | 24시 ~ 9시 강수량 1mm 초과할 경우 1, 아니면 0 |
| RainTomorrow | 범주형 | 목표 변수로 내일 비가왔는지 물음 (비안옴 : 0, 비 옴 : 1) |
1. 데이터의 요약값을 보고 NA값이 10,000개 이상인 열을 제외하고 남은 변수 중 NA값이 있는 행을 제거하시오. 그리고 AUS 데이터의 Date 변수를 Date형으로 변환하고, 전처리가 완료된 weather AUS 데이터를 train(70%), test(30%) 데이터로 분할하시오. (set.seed(6789)를 실행한 후 데이터를 분할하시오.)
import pandas as pd
df = pd.read_csv('../data/weatherAUS.csv')
df.head()
df.isna().sum()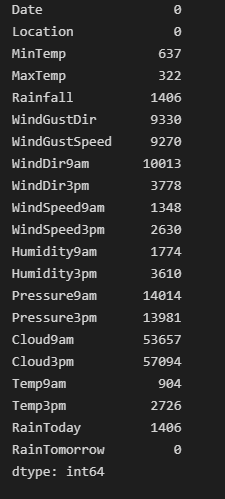
# 결측치가 10000개 이상인 열 삭제
df.drop(columns=['WindDir9am','Pressure9am', 'Pressure3pm', 'Cloud9am', 'Cloud3pm'], axis=1, inplace=True)
df.head()
df.dropna(inplace=True)
df.isna().sum().sum()
#0
# Date 변수를 Date형으로 변환
df['Date'] = pd.to_datetime(df['Date'])
df.info()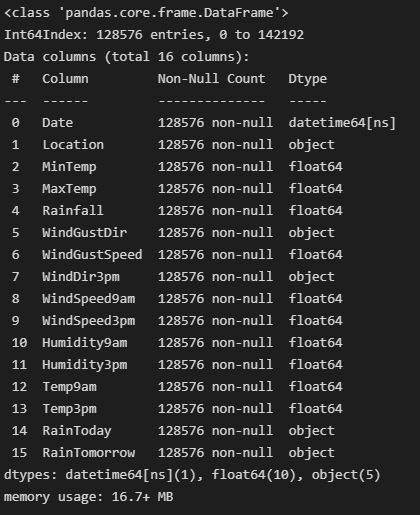
from sklearn.model_selection import train_test_split
X = df.drop(columns=['RainTomorrow','Date'])
y = df['RainTomorrow']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=6789)
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
# (90003, 14) (38573, 14)
# (90003,) (38573,)
2. train데이터로 종속변수인 RainTomorrow(다음날의 강수 여부)를 예측하는 분류모델을 3개 이상 생성하고, test 데이터에 대한 예측값을 csv파일로 각각 제출하시오.
속도 측면에서 LinearRegression, 정확도 측면에서 XGBClassifier, 마지막으로 RandomForestClassifier을 선택하여 모델을 생성한다.
from sklearn.preprocessing import LabelEncoder
features = ['Location','WindGustDir','WindDir3pm', 'RainToday']
for feature in features:
le = LabelEncoder()
X_train[feature] = le.fit_transform(X_train[feature])
X_test[feature] = le.transform(X_test[feature])
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.transform(y_test)
LabelEncoder를 사용하여 범주형 변수 변환
from sklearn.linear_model import LogisticRegression
import time
lr = LogisticRegression()
tic = time.time()
lr.fit(X_train, y_train)
toc = time.time()
print("Time : {}".format(toc-tic))
lr_pred = lr.predict(X_test)
lr_model = pd.DataFrame({'prediction':lr_pred})
lr_model.to_csv('Linear_Regression.csv',index=False)
# Time : 0.5599298477172852
from xgboost import XGBClassifier
xgb = XGBClassifier()
tic = time.time()
xgb.fit(X_train, y_train)
toc = time.time()
print('Time : {}'.format(toc-tic))
xgb_pred = lr.predict(X_test)
xgb_model = pd.DataFrame({'prediction': xgb_pred})
xgb_model.to_csv('XGB.csv', index=False)
# Time : 2.3415465354919434
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
tic = time.time()
rf.fit(X_train, y_train)
toc = time.time()
print("Time : {}".format(toc-tic))
rf_pred = rf.predict(X_test)
rf_model = pd.DataFrame({'prediction':rf_pred})
rf_model.to_csv('RandomForest.csv', index=False)
# Time : 13.661814451217651예상대로 시간은 LinearRegressor가 가장 적게 걸렸으며, RandomForest모델이 가장 오래 걸렸다.
3. 생성된 3개의 분류모델에 대해 성과분석을 실시하여 정확도를 비교하여 설명하시오. 또, ROC curve를 그리고 AUC값을 산출하시오.
import matplotlib.pyplot as plt
from sklearn.metrics import plot_roc_curve, roc_auc_score
# LogisticRegression
plot_roc_curve(lr, X_test, y_test)
plt.show()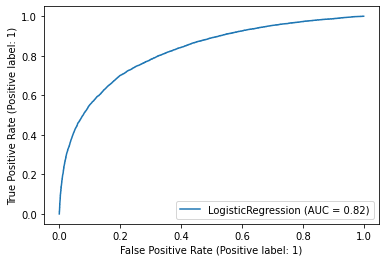
로지스틱 회귀분석의 AUC : 0.82
plot_roc_curve(xgb, X_test, y_test)
plt.show()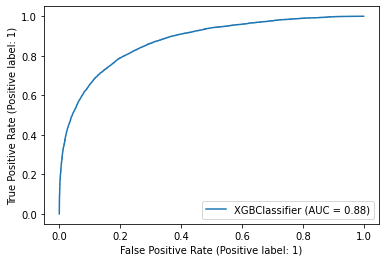
plot_roc_curve(rf, X_test, y_test)
plt.show()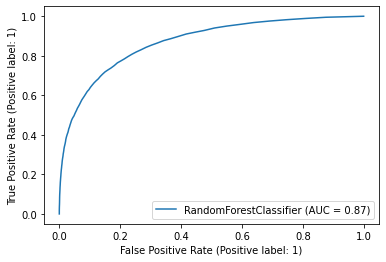
AUC 값은 XGB가 0.88로 가장 높았으며, 그 다음이 RandomForest가 0.87로 높았음
728x90
'adp 실기 > 기출문제' 카테고리의 다른 글
| [Python] 데이터 에듀 ADP 실기 모의고사 4회 3번 파이썬 ver. (비정형 데이터마이닝) (0) | 2022.09.12 |
|---|---|
| [Python] 데이터 에듀 ADP 실기 모의고사 4회 2번 파이썬 ver. (통계분석) (0) | 2022.09.10 |
| [Python] 데이터 에듀 ADP 실기 모의고사 3회 3번 파이썬 ver. (비정형 데이터마이닝) (0) | 2022.09.07 |
| [Python] 데이터 에듀 ADP 실기 모의고사 3회 2번 파이썬 ver. (정형데이터마이닝) (0) | 2022.09.06 |
| [Python] 데이터 에듀 ADP 실기 모의고사 3회 1번 파이썬 ver. (통계 분석) (0) | 2022.09.05 |
'adp 실기/기출문제' Related Articles
more




Comments