
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 빅데이터
- datascience
- 대응표본
- 데이터분석
- ADsP
- LDA
- 빅데이터분석기사
- 언더샘플링
- 독립표본
- pandas
- Python
- 데이터분석전문가
- dataframe
- DBSCAN
- Lambda
- 주성분분석
- 데이터분석준전문가
- numpy
- PCA
- t-test
- 오버샘플링
- 워드클라우드
- opencv
- 파이썬
- 텍스트분석
- 군집화
- 데이터불균형
- 크롤링
- iloc
- ADP
Data Science LAB
[Python] 토픽 모델링 (20 뉴스그룹) 본문
Topic Modeling
토픽 모델링이란 문서 집합에 숨어 있는 주제를 찾아내는 것이다. 머신러닝 기반의 토픽 모델은 숨겨진 주제를 효과적으로 표현할 수 있는 중심 단어를 함축적으로 추출해낸다.
토픽모델링에서는 LDA(Latent Dirichlet Allocation)을 주로 활용한다. 흔히 머신러닝에서 사용하는 LDA(Linear Discriminant Analysis)와는 다른 알고리즘이므로 주의해야한다.
기본 데이터셋인 20뉴스그룹 데이터 셋을 이용하여 토픽모델링을 진행해보려고 한다.
20뉴스그룹 데이터셋에는 20가지의 주제를 가진 뉴스그룹의 데이터가 있는데, 그 중 8개의 주제를 추출하고, 이들 텍스트에 LDA 기반의 토픽 모델링을 적용해보려고 한다.
필요한 라이브러리 로딩 후 카테고리 추출
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
#맥, 윈도우즈, 야구, 하키, 중동, 기독교, 전자공학, 의학 8개 주제 추출
cats = ['comp.sys.mac.hardware','comp.windows.x','rec.sport.baseball','rec.sport.hockey','talk.politics.mideast','soc.religion.christian','sci.electronics','sci.med']
#cats 변수로 기재된 카테고리만 추출
news_df = fetch_20newsgroups(subset='all',remove=('headers','footers','quotos'),categories = cats,random_state=0)
#Count기반의 벡터화만 적용
count_vect = CountVectorizer(max_df=0.95,max_features=1000,min_df=2,stop_words='english',ngram_range=(1,2))
feat_vect = count_vect.fit_transform(news_df.data)
print('CountVectorizer Shape : ',feat_vect.shape)
맥, 윈도우즈, 야구, 하키, 중동, 기독교, 전자공학, 의학 총 8개의 주제를 추출한 후
추출된 텍스트를 Count기반으로 벡터화 변환하였다.
(LDA는 Count기반의 벡터화만 적용 가능함)
CounterVectorizer 객체 변수인 feat_vect는 7855개의 문서가 1000개의 피처로 구성된 행렬데이터이다.
이렇게 피처 벡터화된 데이터셋을 기반으로 LDA 토픽 모델링을 수행하려고 한다.
lda = LatentDirichletAllocation(n_components=8,random_state=0)
lda.fit(feat_vect)
print(lda.components_.shape)
lda.components_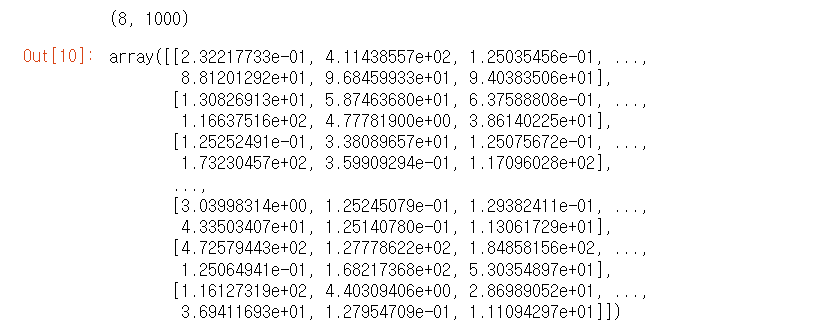
LatentDirichletAllocation의 n_components는 위에서 추출한 주제의 개수와 동일한 8개로 설정하였다.
components는 각 토픽별로 words 피처가 얼마나 많이 그 토픽에 할당 됐는지 수치를 가지고 있다.
(높은 값일 수록 해당 word 피처는 중심 word)
8개의 토픽별로 1000개의 word 피처가 해당 토픽별로 연관도 값을 가지고 있다.
함수 생성
def display_topics(model,feature_names,no_top_words):
for topic_index,topic in enumerate(model.components_):
print('Topic #',topic_index)
#components_array에서 가장 값이 큰 순으로 정렬했을 때, 그 값의 array 인덱스 반환
topic_word_indexes = topic.argsort()[::-1]
top_indexes = topic_word_indexes[:no_top_words]
#top_indexes 대상인 인덱스 별로 feature_names에 해당하는 word feature 추출 후 join으로 concat
feature_concat = ' '.join([feature_names[i] for i in top_indexes])
print(feature_concat)
#CountVectorizer 객체 내의 전체 word의 명칭을 get_features_names()를 통해 추출
feature_names = count_vect.get_feature_names()
#토픽별로 가장 연관도 높은 word 15개씩 추출
display_topics(lda,feature_names,15)
display_topics()함수를 생성하여 각 토픽별로 연관도가 높은 순서대로 words를 출력하였다.
'🛠 Machine Learning > 텍스트 분석' 카테고리의 다른 글
| [Python] 문서 유사도 (0) | 2022.02.25 |
|---|---|
| [Python] 문서 군집화 (0) | 2022.02.24 |
| [Python] SentiWordNet, VADER을 이용한 영화 감상평 감성 분석 (0) | 2022.02.21 |
| [Python] 감성분석 - 비지도 학습 (0) | 2022.02.20 |
| [Python] 감성 분석(Sentiment Analysis) - 지도학습 (0) | 2022.02.19 |
