
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 빅데이터
- 주성분분석
- 언더샘플링
- 데이터불균형
- PCA
- Lambda
- 텍스트분석
- 군집화
- 데이터분석
- 크롤링
- dataframe
- DBSCAN
- t-test
- pandas
- datascience
- Python
- opencv
- 빅데이터분석기사
- numpy
- 독립표본
- iloc
- 대응표본
- 워드클라우드
- ADsP
- LDA
- 데이터분석전문가
- ADP
- 파이썬
- 오버샘플링
- 데이터분석준전문가
Data Science LAB
[Python] 문서 유사도 본문
문서 사이의 유사도 측정은 주로 코사인 유사도(Cosine Similarity)를 사용한다.
벡터의 크기 보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반하여 측정한다.

두 벡터의 사잇각에 따라 상화 관계는 유사하거나 관련이 없거나 아예 반대 관계가 될 수 있다.
두 벡터 A,B의 내적 값은 두 벡터의 크기를 겂한 값에 코사인 각도 값을 곱한 값이다.

따라서 유사도(similarity)는 다음과 같이 두 벡터의 내적을 총 벡터 크기의 합으로 나눈 것이다.
두 넘파이 배열에 대한 코사인 유사도 구하는 함수 생성
import numpy as np
def cos_similarity(v1,v2):
dot_product = np.dot(v1,v2)
l2_norm = (np.sqrt(sum(np.square(v1))) * np.sqrt(sum(np.square(v2))))
similarity = dot_product / l2_norm
return similarity
3개의 간단한 문서들의 유사도 비교
from sklearn.feature_extraction.text import TfidfVectorizer
doc_list = ['if you take the blue pill, the story ends',
'if you take the red pill, you stay in Wonderland',
'if you take the red pill, I show you how deep the rabbit hole goes']
tfidf_vect_simple = TfidfVectorizer()
feature_vect_simple = tfidf_vect_simple.fit_transform(doc_list)
print(feature_vect_simple.shape)
3개의 간단한 문서를 임의로 생성한 뒤,
TfidfVector로 벡터화해 주었다.
#TFidfVectorizer로 transform()한 결과는 희소 행렬이므로 밀집 행렬로 변환
feature_vect_dense = feature_vect_simple.todense()
#첫 번째 문장과 두 번째 문장의 피처 벡터 추출
vect1 = np.array(feature_vect_dense[0]).reshape(-1, )
vect2 = np.array(feature_vect_dense[1]).reshape(-1, )
#첫 번째 문장과 두 번째 문장의 피처 벡터로 두 개 문장의 코사인 유사도 추출
similarity_simple = cos_similarity(vect1,vect2)
print('문장 1,2의 Cosine 유사도 : {0:.3f}'.format(similarity_simple))
앞에서 생성한 결과는 희소 행렬이기 때문에 밀집행렬로 변환해 준 뒤,
3개의 문서중 첫번째와 두 번째 문장의 피처 벡터를 추출하여 두 문장의 코사인 유사도를 측정하였다.
vect3 = np.array(feature_vect_dense[2]).reshape(-1, )
similarity_simple = cos_similarity(vect1,vect3)
print('문장 1,3의 Cosine 유사도 : {0:.3f}'.format(similarity_simple))
similarity_simple = cos_similarity(vect2,vect3)
print('문장 2,3의 Cosine 유사도 : {0:.3f}'.format(similarity_simple))
문장 1,2와 동일하게 각 문장 별로 유사도 비교를 해보았다.
Sklearn를 활용한 문서 유사도 측정
from sklearn.metrics.pairwise import cosine_similarity
similarity_simple_pair = cosine_similarity(feature_vect_simple[0],feature_vect_simple)
print(similarity_simple_pair)
cosine_similarity()는 희소 행렬, 밀집 행렬 모두가 가능하며 배열 또한 가능하다.
따라서 별도의 변환 작업이 필요하지 않다.
첫번째 문장과, 문장 3개의 문서 유사도 측정 결과
1은 자기 자신과의 유사도 측정 결과이며,
문서 1과 2의 유사도는 0.402, 문서 1과 3의 유사도는 0.404로 측정되었다.
similarity_simple_pair = cosine_similarity(feature_vect_simple[0],feature_vect_simple[1:])
print(similarity_simple_pair)
자기 자신과의 문서 유사도를 없애고 싶다면
[1:]을 추가하면 제거할 수 있다.
similarity_simple_pair = cosine_similarity(feature_vect_simple, feature_vect_simple)
print(similarity_simple_pair)
print('similarity_simple_pair shape : ',similarity_simple_pair.shape)
첫 번째 로우는 1번 문서와 2,3번째 문서와의 유사도를 나타낸다.
Opinion Reveiw 데이터 셋을 이용한 문서 유사도 측정
from nltk.stem import WordNetLemmatizer
import nltk
import string
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
Lemmatization을 구현하는 LemNormalize() 함수를 생성하였다.
import pandas as pd
import glob ,os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
path = r'C:\Users\OpinosisDataset1.0\OpinosisDataset1.0\topics'
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
for file_ in all_files:
df = pd.read_table(file_,index_col=None, header=0,encoding='latin1')
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
filename_list.append(filename)
opinion_text.append(df.to_string())
document_df = pd.DataFrame({'filename':filename_list, 'opinion_text':opinion_text})
tfidf_vect = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english' , \
ngram_range=(1,2), min_df=0.05, max_df=0.85 )
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
km_cluster = KMeans(n_clusters=3, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
document_df['cluster_label'] = cluster_label
문서 군집화와 동일하게 디렉토리의 파일들을 모두 불러와 리스트로 저장하고,
n=3으로 설정하여 KMeans 군집화를 진행하였다.
호텔을 주제로 군집화된 문서와 다른 문서와의 유사도 측정
from sklearn.metrics.pairwise import cosine_similarity
#호텔로 군집화된 문서의 인덱스 추출
hotel_indexes = document_df[document_df['cluster_label']==1].index
print("호텔로 군집화된 문서의 DataFrame Index : ",hotel_indexes)
#그중 첫 번째 문서 추출해 파일명 표시
comparison_docname = document_df.iloc[hotel_indexes[0]]['filename']
print('비교 문서명',comparison_docname, '와 타 문서 유사도')
#document_df에서 추출한 Index 객체를 feature_vect로 입력하여 호텔 군집화된 feature_vect 추출
similarity_pair = cosine_similarity(feature_vect[hotel_indexes[0]], feature_vect[hotel_indexes])
print(similarity_pair)
호텔을 주제로 군집화된 문서의 인덱스 추출 -> TfidfVectorizer 객체 변수인 feature_vect에서 호텔로 군집화된 문서의 피처벡터 추출
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#첫 번째 문서와 타 문서 간 유사도가 큰 순으로 정렬한 인덱스를 추출하되 자기 자신 제외
sorted_index = similarity_pair.argsort()[:,::-1]
sorted_index = sorted_index[:,1:]
#유사도가 큰 순으로 hotel_indexes 추출해 재정렬
hotel_sorted_indexes = hotel_indexes[sorted_index.reshape(-1)]
#유사도가 큰 순으로 유사도 값 재정렬 하되 자기 자신 제외
hotel_1_sim_value = np.sort(similarity_pair.reshape(-1))[::-1]
hotel_1_sim_value = hotel_1_sim_value[1:]
#유사도가 큰 순으로 정렬된 인덱스와 유사도 값을 이용해 파일명과 유사도 값을 막대 그래프로 시각화
hotel_1_sim_df = pd.DataFrame()
hotel_1_sim_df['filename'] = document_df.iloc[hotel_sorted_indexes]['filename']
hotel_1_sim_df['similarity'] = hotel_1_sim_value
sns.barplot(x='similarity',y='filename',data = hotel_1_sim_df)
plt.title(comparison_docname)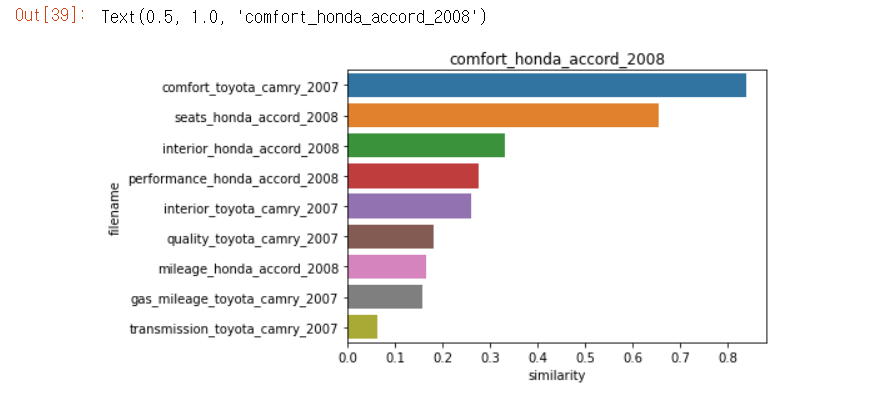
유사도가 높은 순으로 정렬 후 시각화
'🛠 Machine Learning > 텍스트 분석' 카테고리의 다른 글
| [Python] 한글 텍스트 처리 - 네이버 영화 평점 감성 분석 (0) | 2022.02.26 |
|---|---|
| [Python] 문서 군집화 (0) | 2022.02.24 |
| [Python] 토픽 모델링 (20 뉴스그룹) (0) | 2022.02.22 |
| [Python] SentiWordNet, VADER을 이용한 영화 감상평 감성 분석 (0) | 2022.02.21 |
| [Python] 감성분석 - 비지도 학습 (0) | 2022.02.20 |