
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- DBSCAN
- 워드클라우드
- pandas
- 크롤링
- ADsP
- 언더샘플링
- LDA
- t-test
- opencv
- ADP
- iloc
- 데이터불균형
- Python
- 독립표본
- PCA
- numpy
- 주성분분석
- 대응표본
- 데이터분석준전문가
- 데이터분석
- 군집화
- 빅데이터분석기사
- Lambda
- 파이썬
- 오버샘플링
- 빅데이터
- 텍스트분석
- dataframe
- datascience
- 데이터분석전문가
Archives
Data Science LAB
[Python] 선형 회귀분석 본문
728x90
하나 혹은 그 이상의 원인이 종속변수에 미치는 영향을 추적하여 식으로 표현하는 통계기법으로 머신러닝과 다르게 식으로 표현하기 때문에 해석력을 높일 수 있다.

선형 회귀분석의 평가
SST : 총변동
SSE : 설명된 변동
SSR : 설명되지 않은 변동을 의미

위의 수식이 의미하는 바는 총 변동 중 설명된 변동의 비율이다.
즉, 회귀 추정선이 전체 데이터를 얼마나 설명하고 있는지를 의미하며 이 값이 높다면 회귀 추정 직선으로 새로운 값을 예측하거나 추정하더라도 믿을 수 있는 정도를 의미한다.

RMSE 값은 평균 제곱근 오차로 예측값에서 실제 관측값을 뺀 값의 제곱의 합을 표본의 수로 나눈 것이다. SSE값을 자유도 (n-2)로 나누고 루트를 취한 값과 같다. RMSE 값이 낮을 수록 예측력이 좋다고 할 수 있다.
statsmodels.formula.api.ols(formula, data, subset=None, drop_cols=None, *arg, **kwargs)
| models.summary() | 모델 적합 결과 요약 제시 |
| models.params | 변수의 회귀계수 |
| model.predict() | 새로운 데이터에 대한 예측값 |
import pandas as pd
import numpy as np
house = pd.read_csv('../data/kc_house_data.csv')
house = house[['price', 'sqft_living']]
# 독립변수와 종속변수의 선형 가정
house.corr()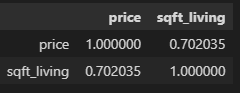
독립변수와 종속변수의 상관계수가 0.7로 양의 상관관계가 있음을 확인
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
y = house['price']
X = house['sqft_living']
#단순 선형 회귀 모형 적합
lr = ols('price ~ sqft_living', data=house).fit()
y_pred = lr.predict(X)
plt.scatter(X,y)
plt.plot(X, y_pred, color='red')
plt.xlabel('sqft_living', fontsize=10)
plt.ylabel('price', fontsize=10)
plt.title('Linear Regression Result')
plt.show()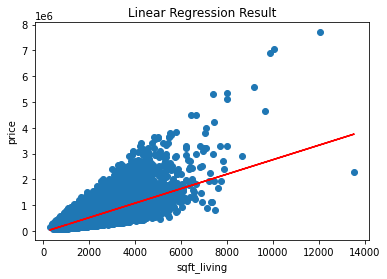
단순 선형 회귀분석으로는 설명이 불가능한 형태임
lr.summary()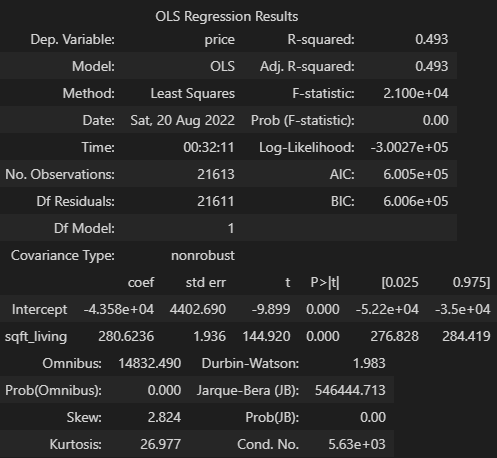
다중 선형 회귀분석
- 독립변수의 수가 두 개 이상이면 필수적으로 다중공선성의 문제를 해결해야 함
- 독립변수들 간의 상관계수를 구해 상관성을 직접파악하고 상관성이 0.9 이상이면 다중공선성이 있다고 판단
- 다중공선성이 의심되는 두 독립변수의 회귀분석으로 허용 오차를 구했을 때 0.1 이하이면 다중공선성 문제가 심각하다고 할 수 있음
- VIF가 10 이상이면 다중공선성이 존재함
import pandas as pd
cars = pd.read_csv('../data/Cars93.csv')
cars.info()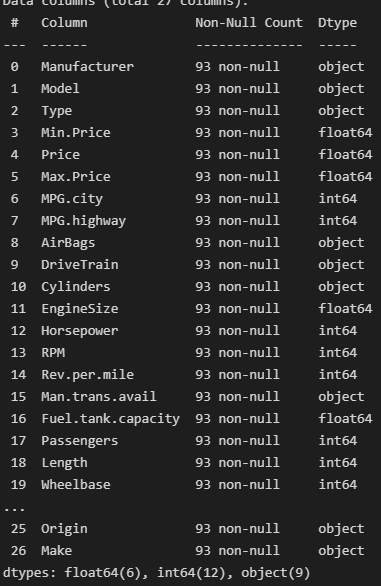
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
#컬럼의 특수 문자 제거
cars.columns = cars.columns.str.replace('.', "")
model = smf.ols(formula='Price ~ EngineSize + RPM + Weight + Length + MPGcity + MPGhighway', data=cars)
result = model.fit()
result.summary()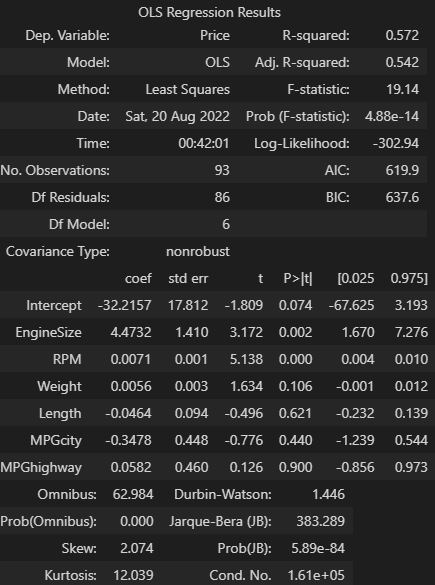
cars[['EngineSize', 'RPM', 'Weight', 'Length', 'MPGcity', 'MPGhighway']].corr()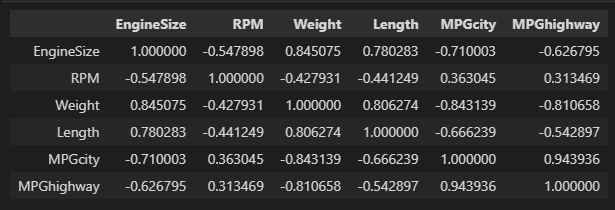
from patsy import dmatrices
from statsmodels.stats.outliers_influence import variance_inflation_factor
y, X = dmatrices('Price ~ EngineSize + RPM + Weight + Length + MPGcity + MPGhighway',
data = cars, return_type ='dataframe')
# 독립변수끼리의 VIF값을 계산하여 데이터 프레임으로 만듦
vif_list = []
for i in range(1, len(X.columns)):
vif_list.append([variance_inflation_factor(X.values, i), X.columns[i]])
pd.DataFrame(vif_list, columns=['vif', 'variable'])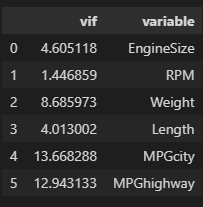
model = smf.ols(formula = 'Price ~ EngineSize + RPM + Weight + MPGhighway', data = cars)
result = model.fit()
result.summary()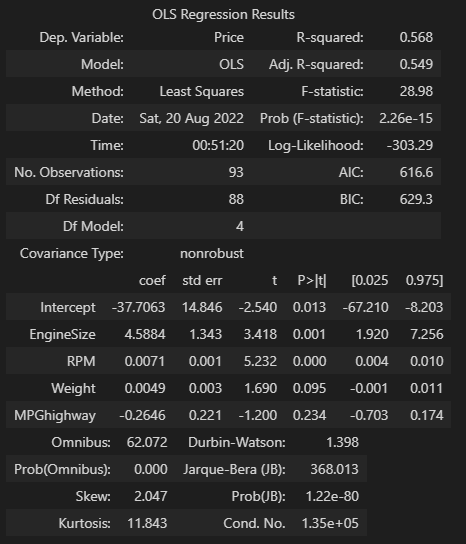
from concurrent.futures import process
import time
import itertools
def processSubset(X,y, feature_set):
model = sm.OLS(y, X[list(feature_set)])
regr = model.fit()
AIC = regr.aic
return {'model':regr, 'AIC':AIC}
#전진 선택법
def forward(X,y,predictors):
# 변수들이 미리 정의된 predictors에 있는 지 없는 지 확인
remaining_predictors = [p for p in X.columns.difference(['Intercept']) if p not in predictors]
results = []
for p in remaining_predictors:
results.append(processSubset(X=X, y=y, feature_set=predictors+[p]+['Intercept'] ))
#데이터프레임으로 변환
models = pd.DataFrame(results)
#AIC가 가장 낮은 것을 선택
best_model = models.loc[models['AIC'].argmin()] # index
print('Processed ', models.shape[0], 'models on',len(predictors)+1, 'predictors in')
print('Selected predictors : ', best_model['model'].model.exog_names,
'AIC : ', best_model[0])
return best_model
#후진 소거법
def backward(X,y,predictors):
tic = time.time()
results = []
for combo in itertools.combinations(predictors, len(predictors) -1):
results.append(processSubset(X=X, y=y, feature_set=list(combo) + ['Intercept']))
models = pd.DataFrame(results)
#가장 낮은 AIC를 가진 모델을 선택
best_model = models.loc[models['AIC'].argmin()]
toc = time.time()
print('Processed ', models.shape[0],
'models on', len(predictors)-1,
'predictors in', (toc-tic))
print('Selected predicors : ', best_model['model'].model.exog_names,
'AIC :',best_model[0])
return best_model
#단계적 선택법
def Stepwise_model(X,y):
Stepmodels = pd.DataFrame(columns = ['AIC','model'])
tic = time.time()
predictors = []
Smodel_before = processSubset(X,y,predictors+['Intercept'])['AIC']
for i in range(1, len(X.columns.difference(['Intercept'])) +1):
Forward_result = forward(X=X, y=y, predictors=predictors)
print('forward')
Stepmodels.loc[i] = Forward_result
predictors = Stepmodels.loc[i]['model'].model.exog_names
predictors = [k for k in predictors if k!='Intercept']
Backward_result = backward(X=X, y=y, predictors=predictors)
if Backward_result['AIC'] < Forward_result['AIC']:
Stepmodels.loc[i] = Backward_result
predictors = Stepmodels.loc[i]['model'].model.exog_names
Smodel_before = Stepmodels.loc[i]['AIC']
predictors = [k for k in predictors if k!='Intercept']
print('backward')
if Stepmodels.loc[i]['AIC'] > Smodel_before:
break
else:
Smodel_before = Stepmodels.loc[i]['AIC']
toc = time.time()
print('Total elapsed time : ',(toc-tic), 'Seconds.')
return (Stepmodels['model'][len(Stepmodels['model'])])
Stepwise_best_model = Stepwise_model(X=X, y=y)
Stepwise_best_model.summary()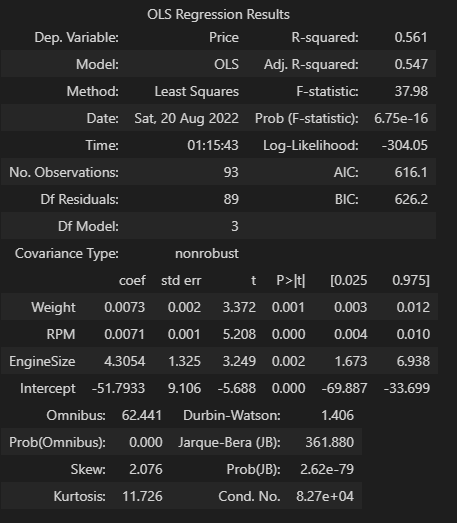
파이썬이 편하긴 하지만 변수선택법 만큼은 코드 구현하는게 너무 복잡해서 만약 ADP 시험에 나온다면,,, R로 할 것같다

728x90
'🛠 Machine Learning > 기초 통계' 카테고리의 다른 글
| [Python] 탐색적 요인분석 (FA) (0) | 2022.09.19 |
|---|---|
| [Python] 다항 회귀분석 (Polynomial Regression) (0) | 2022.08.24 |
| [Python] 교차 분석 (카이제곱 검정) (0) | 2022.08.21 |
| [Python] 이원 배치 분산 분석 (Two-way ANOVA) (0) | 2022.08.20 |
| [Python] 일원 분산 분석(ANOVA) (0) | 2022.03.16 |
'🛠 Machine Learning/기초 통계' Related Articles
more




Comments