
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터불균형
- PCA
- t-test
- 크롤링
- 데이터분석
- 데이터분석준전문가
- 군집화
- ADP
- ADsP
- numpy
- iloc
- dataframe
- 언더샘플링
- Lambda
- 독립표본
- datascience
- 빅데이터
- opencv
- 데이터분석전문가
- 주성분분석
- LDA
- 파이썬
- Python
- 워드클라우드
- 대응표본
- DBSCAN
- 텍스트분석
- 빅데이터분석기사
- pandas
- 오버샘플링
Data Science LAB
[Python] PCA 예제 본문
2022.03.05 - [Python] PCA(Principal Component Analysis)
[Python] PCA(Principal Component Analysis)
PCA 개요 PCA(Principal Component Analysis)는 가장 대표적인 차원 축소 기법으로 여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분(Principal Component)를 추출해 차원을 축소하는 기법이다.
suhye.tistory.com
지난 포스팅에서 공부했었던 PCA를 다른 데이터셋을 이용하여 실습해 보려고 한다.
데이터셋 다운로드
https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients
UCI Machine Learning Repository: default of credit card clients Data Set
default of credit card clients Data Set Download: Data Folder, Data Set Description Abstract: This research aimed at the case of customers’ default payments in Taiwan and compares the predictive accuracy of probability of default among six data mini
archive.ics.uci.edu
데이터셋 로딩
import pandas as pd
df = pd.read_excel('default of credit card clients.xls',header=1,sheet_name='Data').iloc[0:,1:]
print(df.shape)
df.head()
#DataFrame으로 변환
df.rename(columns = {'PAY_0':'PAY1','default payment next month':'default'},inplace=True)
y_target = df['default']
X_features = df.drop('default',axis=1)
속성간의 상관도를 heatmap으로 시각화
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
corr = X_features.corr()
plt.figure(figsize=(14,14))
sns.heatmap(corr,annot=True,fmt='.1g')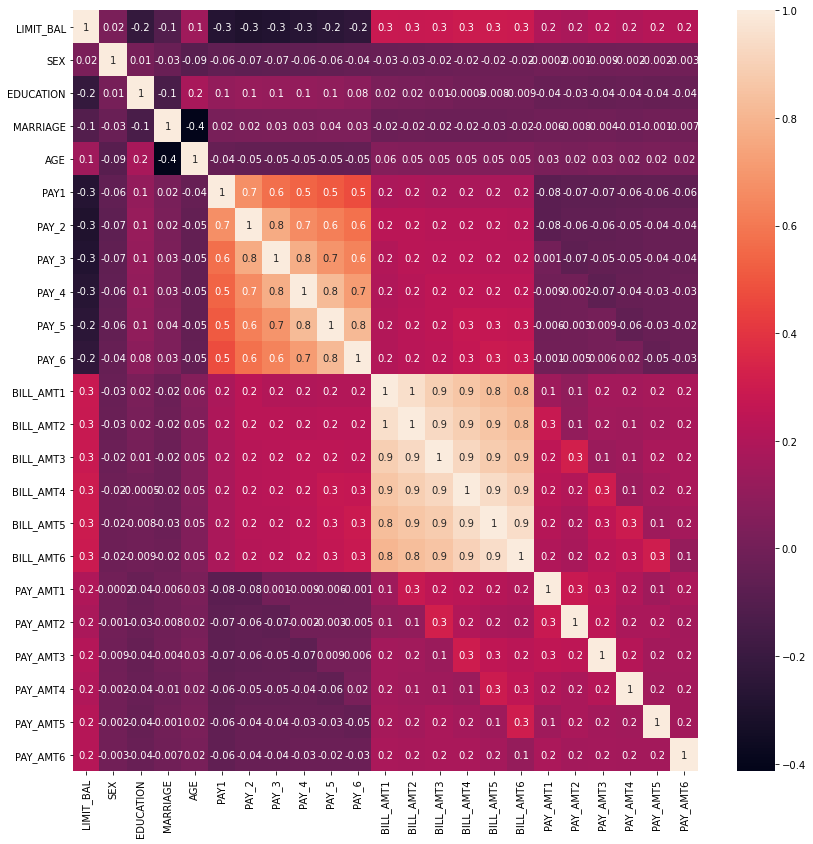
BILL_AMTI1 ~ BILL_AMTI6의 6개 속성끼리의 상관도가 대부분 0.9 이상으로 매우 높은 것을 알 수 있다.
또한, PAY_1 ~ 6의 상관도 역시 높다. 이렇게 높은 상관도를 가진 속성들은 소수의 PCA만으로도 자연스럽게 이 속성들의 변동성을 수용할 수 있다.
bill_amti1~6의 속성끼리 상관도가 매우 높아 PCA로 2개 속성으로 변환
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
#BILL_AMT 6개 속성명 생성
cols_bill = ['BILL_AMT'+str(i) for i in range(1,7)]
print("대상 속성명 : ",cols_bill)
#2개의 PCA 속성을 가진 PCA 객체 생성, explained_variance_ratio 계산을 위해 fit() 호출
scaler = StandardScaler()
df_cols_scaled = scaler.fit_transform(X_features[cols_bill])
pca = PCA(n_components=2)
pca.fit(df_cols_scaled)
print("PCA Components별 변동성 : ",pca.explained_variance_ratio_)
2개의 PCA Components 만으로 6개의 속성의 변동성을 약 95%이상 설명할 수 있으며 특히 첫 번째 PCA 축은 90%의 변동성을 수용할 수 있다.
원본 데이터셋 VS PCA 변환 데이터셋 분류 예측 결과 비교
- 원본데이터셋에 랜덤포레스트 적용
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
rf = RandomForestClassifier(n_estimators=300,random_state = 156)
scores = cross_val_score(rf,X_features,y_target,scoring='accuracy',cv=3)
print("CV=3인 경우의 개별 Fold세트별 정확도 : ",scores)
print("평균 정확도 : {0:.4f}".format(np.mean(scores)))
-PCA 변환 데이터셋에 랜덤포레스트 적용
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_scaled = scaler.fit_transform(X_features)
pca = PCA(n_components = 6)
df_pca = pca.fit_transform(df_scaled)
scores_pca = cross_val_score(rf,df_pca,y_target,scoring='accuracy',cv=3)
print("CV=3인 경우의 PCA 개별 Fold 세트별 정확도 : ",scores_pca)
print("PCA 변환 데이터 세트 평균 정확도 : {0:.4f}".format(np.mean(scores_pca)))
전체 23개 속성중 6개의 PCA 컴포넌트만으로도 원본 데이터를 기반으로 한 분류 예측 결과보다 약 1~2%의 예측 성능 저하가 발생하였다. 전체 속성의 ¼수준으로 이정도 수치의 예측 성능을 유지할 수 있는 것은 PCA의 성능을 잘 나타낸다.
'🛠 Machine Learning > 차원 축소' 카테고리의 다른 글
| [Python]NMF (0) | 2022.03.08 |
|---|---|
| [Python] SVD(Singular Value Decomposition) (0) | 2022.03.07 |
| [Python] LDA(Linear Discriminant Analysis) (0) | 2022.03.07 |
| [Python] PCA(Principal Component Analysis) (0) | 2022.03.05 |



