
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Lambda
- 데이터불균형
- 크롤링
- ADP
- Python
- iloc
- 주성분분석
- t-test
- 오버샘플링
- PCA
- 빅데이터
- 빅데이터분석기사
- 텍스트분석
- 데이터분석준전문가
- dataframe
- pandas
- 데이터분석전문가
- 독립표본
- opencv
- datascience
- 군집화
- DBSCAN
- 워드클라우드
- ADsP
- LDA
- 파이썬
- numpy
- 대응표본
- 언더샘플링
- 데이터분석
Archives
Data Science LAB
[Python] 데이터 에듀 ADP 실기 모의고사 2회 2번 파이썬 ver. (정형데이터마이닝) 본문
728x90
사용 데이터 : titanic.csv
| 변수 | 데이터 형태 | 설명 |
| pclass | 수치형 | 1,2,3 등석 정보를 각각 1,2,3으로 저장 |
| survived | 범주형 | 생존 여부 (0 : 사망, 1 : 생존) |
| name | 문자형 | 이름 |
| sex | 수치형 | 성별 |
| age | 수치형 | 나이 |
| sibsp | 수치형 | 함께 탑승한 형제 또는 배우자의 수 |
| parch | 수치형 | 함꼐 탑승한 형제 또는 자녀의 수 |
| ticket | 문자형 | 티켓번호 |
| fare | 수치형 | 티켓요금 |
| cabin | 문자형 | 선실번호 |
| embarked | 범주형 | 탑승한곳(C:cherbourg, Q:Queenstown, S:Southampthon) |
1. cabin, embarked 변수의 값 중 ""로 처리된 값을 NA로 바꾸고 아래의 데이터 테이블을 보고 문자형, 범주형 변수들을 각각 charactor, factor형으로 변환하시오.
또, 수치형 변수가 NA인 값을 중앙값으로 대체하고, 범주형 변수가 NA인 값을 최빈값으로 대체하고 age 변수를 아래의 표와 같이 구간화하여 age_1이라는 변수를 생성하고 추가하시오.
import pandas as pd
import numpy as np
df = pd.read_csv('../data/titanic.csv')
df.head()
df.info()
df[['cabin', 'embarked']].replace("", np.nan)
replace 함수를 사용해서 " "(공백)을 NA로 변환함
df['survived'] =df['survived'].astype('category')
df[['name', 'ticket']] = df[['name', 'ticket']].astype('str')
df.dtypes
survived -> factor, name -> charactor, ticket -> charctor로 변환
df.isna().sum()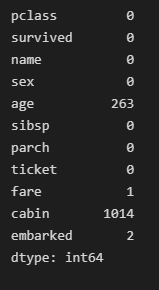
df['age'] = df['age'].fillna(df['age'].median())
df['fare'] = df['fare'].fillna(df['fare'].mean())
df['cabin'] = df['cabin'].fillna(df['cabin'].mode()[0])
df['embarked'] = df['embarked'].fillna(df['embarked'].mode()[0])
df.isna().sum()
수치형 변수가 NA인 값을 중앙값, 범주형 변수가 NA인 값을 최빈값으로 대체
bins = [0,10,20,30,40,50,60,70,80,90]
labels = [0,1,2,3,4,5,6,7,8]
df['age_1'] = pd.cut(df['age'], bins, right=False,labels=labels)
df.head()
age 변수를 구간화 하여 새로운 변수 생성
2. 전처리가 완료된 데이터를 train(70%), test(30%) 데이터로 분할하시오. (set.seed(12345)) 를 실행한 후 데이터를 분할하시오. 또, train 데이터로 종속변수인 survived(생존 여부)를 독립변수 pclass, sex, sibsp, parch, fare, embarked로 지정하여 예측하는 분류모델을 3개이상 생성하고, test데이터에 대한 예측값을 csv파일로 각각 제출하시오.
from sklearn.model_selection import train_test_split
X = df[['pclass', 'sex', 'sibsp', 'parch', 'fare', 'embarked']]
y = df['survived']
X = pd.get_dummies(X, drop_first=True)
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=12345)
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
범주형 변수 더미 변환 후 train/test 데이터로 분할
from sklearn.linear_model import LogisticRegression
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
import time
lr = LogisticRegression()
xgb = XGBClassifier()
rf = RandomForestClassifier()
def model_result(model,csv_name):
start = time.time()
model.fit(X_train, y_train)
end = time.time()
print(f"{end-start : .5f} sec")
pred = model.predict(X_test)
pred_data = pd.DataFrame(pred, columns=['prediction'])
pred_data.to_csv('{}_predict.csv'.format(csv_name))
모델 생성 후 결과를 csv형태로 내보내는 함수 생성
model_result(lr,'LogisticRegression')
# 0.01921 sec
model_result(xgb,'XGb')
# 0.07932 sec
model_result(rf,'RandomForestClassifier')
# 0.13900 sec
속도 측면에서 LinearRegressor, 정확도 측면에서 XGBoost를 선택하였고, RandomForest를 이용하여 추가 모델링을 진행함 -> 속도측면에서는 LinearRegressor가 빠른 것을 확인
3. 생성된 3개의 분류모델에 대해 성과분석을 실시하여 정확도를 비교하여 설명하시오. 또, ROC curve를 그리고 AUC값을 산출하시오.
from sklearn.metrics import roc_auc_score, plot_roc_curve
import matplotlib.pyplot as plt
# LogisticRegression
lr_pred = lr.predict(X_test)
print(roc_auc_score(y_test, lr_pred))
plot_roc_curve(lr, X_test, y_test)
plt.show()
# 0.7569340128755364
xgb_pred = xgb.predict(X_test)
print(roc_auc_score(y_test, xgb_pred))
plot_roc_curve(xgb, X_test, y_test)
plt.show()
# 0.7637473175965666
rf_pred = rf.predict(X_test)
print(roc_auc_score(y_test, rf_pred))
plot_roc_curve(rf, X_test, y_test)
plt.show()
# 0.7370171673819742
생성된 세 모델의 정확도는 xgb, logisticregression, randomforestclassifier 순서대로 높았으며, 큰 차이는 없지만 AUC값 또한 xgb가 가장 높았다.
728x90
'adp 실기 > 기출문제' 카테고리의 다른 글
| [Python] 데이터 에듀 ADP 실기 모의고사 3회 1번 파이썬 ver. (통계 분석) (0) | 2022.09.05 |
|---|---|
| [Python] 데이터 에듀 ADP 실기 모의고사 2회 3번 파이썬 ver. (비정형 데이터마이닝) (0) | 2022.09.04 |
| [Python] 데이터 에듀 ADP 실기 모의고사 2회 1번 파이썬 ver. (통계분석) (0) | 2022.09.01 |
| [Python] 데이터 에듀 ADP 실기 모의고사 1회 3번 파이썬 ver. (비정형 텍스트마이닝) (0) | 2022.08.31 |
| [Python] 데이터 에듀 ADP 실기 모의고사 1회 2번 파이썬 ver (통계분석) (0) | 2022.08.30 |
'adp 실기/기출문제' Related Articles
more




Comments