
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 대응표본
- 데이터분석전문가
- PCA
- pandas
- 빅데이터분석기사
- ADsP
- 파이썬
- 워드클라우드
- 데이터분석준전문가
- 데이터분석
- 주성분분석
- dataframe
- DBSCAN
- 크롤링
- 오버샘플링
- 언더샘플링
- opencv
- 텍스트분석
- Lambda
- 독립표본
- ADP
- 군집화
- 빅데이터
- 데이터불균형
- LDA
- Python
- numpy
- t-test
- datascience
- iloc
Data Science LAB
[Python] 데이터 결측치 처리 본문
Pandas 에서는 다양한 방법으로 결측치(NA)를 처리할 수 있다.
결측치란, 컬럼에 값이 없는 NULL 상태의 데이터를 말하며, 데이터셋을 머신러닝 모델에 적용할 때 결측치가 존재하면 문제가 발생하기 때문에 다른 값으로 대체하거나 삭제해야한다.

데이터의 결측 여부 확인
import pandas as pd
import numpy as np
data = pd.read_csv("titanic_train.csv")
data.head()
먼저, 유명한 분류 데이터셋 중 하나인 타이타닉 데이터셋을 불러온다.
data.isna()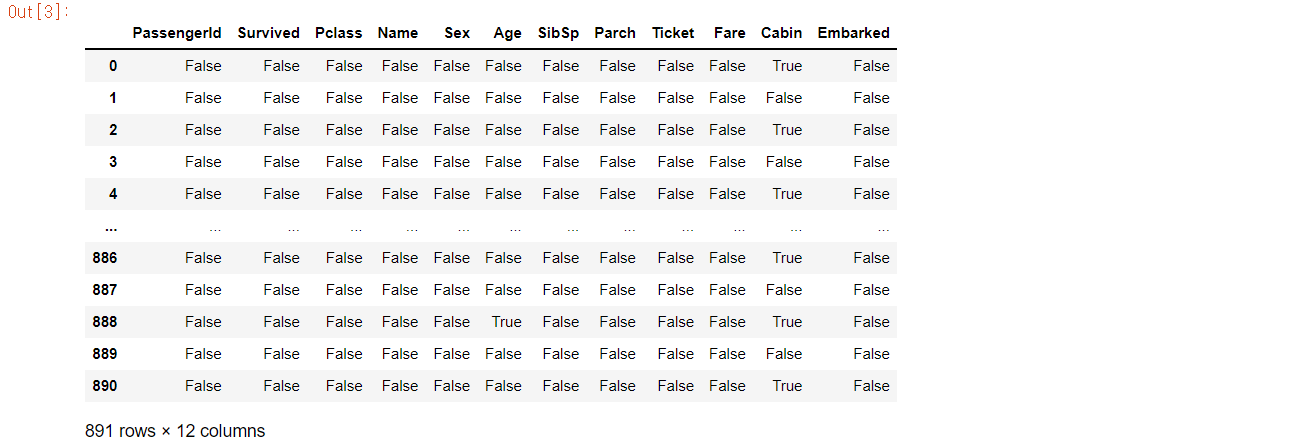
isna()를 사용하면 데이터가 결측인지 아닌지에 대해 True/False로 반환해준다.
True -> 결측
False -> 결측 X
data.isna().sum()
isna에 sum()함수를 추가해 주면,
각 컬럼별 결측 데이터의 수를 반환해 준다.
titanic 데이터셋에서는 'Age'컬럼의 결측치가 177개, 'Cabin' 칼럼의 결측치가 678개, 'Embarked'컬럼의 결측치가 2개인 것으로 확인할 수 있다.
결측 데이터 대치
결측 데이터가 존재하는 것을 확인했다면, 특정 값으로 대체하여 데이터셋을 채울 수 있다.
대치값 종류
- 최빈값(mode)
- 평균(mean)
- 중앙값(median)
- 조건부 대치
- 회귀분석을 통한 대치
- 임의의 값으로 전체 결측치 대치
data.fillna(0)fillna()에 대치하고자 하는 임의의 값을 입력하면, 전체 결측치가 하나의 값으로 대치된다.
- 결측치 이전 값으로 대치
data.fillna(method='pad')
- 결측치 이후 값으로 대치
data.fillna(method = 'bfill')
- 평균값 대치
data['Age'].fillna(data['Age'].mean(),inplace=True)fillna()함수를 통해 평균값으로 대치할 수 있다.
📍inplace = True 로 설정해야 실제 데이터 셋 값이 변경된다.
data['Age'] = data['Age'].fillna(data['Age'].mean(),inplace=False)inplace 파라미터의 default 값은 False 이며, default 값을 사용하고 싶은 경우,
왼쪽에 대치하고자하는 컬럼을 한번 더 선언하여 fillna()값을 대입하면 된다.
결측 데이터 삭제
- 결측치 행 삭제
data = data.dropna()dropna()함수를 사용하면 결측치를 삭제할 수 있다.
data.dropna(inplace=True)dropna()도 마찬가지로 inplace=True로 설정해야 바로 결측치 삭제가 적용된다.
-행 전체가 결측치인 행 삭제
data = data.dropna(how='all')
-행의 결측치가 n개 초과인 행 삭제
data = data.dropna(thresh=n)
- 결측치가 존재하는 모든 컬럼 삭제
data = data.dropna(axis=1)
- 특정 컬럼 중 결측치가 존재할 때 행 삭제
data = data.dropna(subset = ['Age','Cabin','Embarked'])
결측치 처리 가이드라인
- 10% 미만 : 삭제 또는 대치
- 10~50% : regression or model based imputation
- 50% 이상 : 해당 컬럼 삭제
'🐍 Python > Pandas' 카테고리의 다른 글
| [Python] Pandas iterrows()로 데이터프레임의 행 반복 (0) | 2022.08.12 |
|---|---|
| [python] df.columns.difference (0) | 2022.03.27 |
| [Python] Apply lambda 적용 (0) | 2022.03.10 |
| [Python] loc/iloc 차이점 (0) | 2022.03.10 |
| [Python] 리스트, 딕셔너리, array 데이터프레임으로 변환 (0) | 2022.02.16 |



