
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ADP
- 독립표본
- 언더샘플링
- 빅데이터
- Lambda
- LDA
- 파이썬
- iloc
- 빅데이터분석기사
- ADsP
- 오버샘플링
- pandas
- 군집화
- 워드클라우드
- 데이터분석
- dataframe
- Python
- DBSCAN
- 데이터분석준전문가
- 크롤링
- t-test
- 주성분분석
- 데이터분석전문가
- numpy
- 텍스트분석
- PCA
- datascience
- opencv
- 데이터불균형
- 대응표본
Data Science LAB
[Python]뉴스기사 크롤링(Newspaper 이용) 본문
이번에는 newpaper 라이브러리를 이용하여 웹사이트의 뉴스 기사를 크롤링 해보려고 합니다.
https://www.3gpp.org/news-events/2143-3gpp-meets-imt-2020
3GPP meets IMT-2020
November 28, 2020 Earlier this week the ITU issued a press release to publicise the move to the approval process - by the 193 member states of the Union - of their ITU-R Recommendation: 'Detailed specifications of the radio interfaces of IMT-2020.' (ITU-R
www.3gpp.org
1. 라이브러리 및 데이터 불러오기
!pip install newspaper3k
import newspaper
from newspaper import Article
article = Article("https://www.3gpp.org/news-events/2143-3gpp-meets-imt-2020")
#기사 다운로드
article.download()
article.parse()파이썬3 사용중이면
pip install newspaper3k
파이썬 2 사용중이면
pip install newspaper
(저는 파이썬 3 사용했기 때문에 newspaper3k로 했습니다!)
2. 기사 정보 확인
- 기사 내용
print(article.text)
- 기사 제목
article.title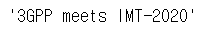
- 기사 저자
article.authors
이번에는 techcrunch 사이트에서 기사들을 크롤링 해보려고 합니다!
TechCrunch – Startup and Technology News
TechCrunch - Reporting on the business of technology, startups, venture capital funding, and Silicon Valley
social.techcrunch.com
테크크런치는 기술 산업 뉴스의 온라인 출판사로 각종 기술과 기업의 기사들이 올라와 있습니다.
라이브러리는 위에서 설명한 것과 동일하기 때문에 다시 불러오지 않도록 하겠습니당(/▽\)
1. 사이트에서 기사 불러오기
site = newspaper.build('https://techcrunch.com/')
site.article_urls()
사이트 제일 위에 올라오는 기사가 시간에 따라 매번 달라져서 하는 시간에 따라 크롤링 된 기사가 다를 수 있다!
site_article = site.articles[0]
site_article.download()
site_article.parse()
print("article title : ",site_article.title)
print("article url : ",site_article.url)마찬가지로 제일 윗줄의 기사는 변동 가능합니댱
2. for 함수를 이용해 기사 저장
allarticles = []
for i in range(len(site.article_urls())):
article = Article(site.article_urls()[i])
article.download()
article.parse()
allarticles.append(article)
3. 크롤링 해온 데이터를 데이터 프레임 형식으로 저장
import pandas as pd
df = pd.DataFrame(columns=['Title','Autrhors','PubDate','URL','Text'])
for i in range(len(allarticles)):
row = dict(zip(['Title','Autrhors','PubDate','URL','Text'],
[allarticles[i].title,allarticles[i].authors,allarticles[i].publish_date,allarticles[i].url,allarticles[i].text]))
row_s = pd.Series(row)
row_s.name=i
df = df.append(row_s)
df
이런식으로 기사의 제목, 저자, 출판일, URL, 내용이 잘 저장된 것을 확인할 수 있습니다
'🐍 Python > Crawling' 카테고리의 다른 글
| [Python]Tabular Data 웹에서 크롤링 (0) | 2022.02.13 |
|---|---|
| [Python] 웹에서 사진 크롤링하기(Crawling) (0) | 2022.02.06 |

