
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 오버샘플링
- Python
- t-test
- 대응표본
- ADP
- dataframe
- 주성분분석
- iloc
- 텍스트분석
- datascience
- 독립표본
- 데이터분석준전문가
- 데이터분석
- Lambda
- 파이썬
- 크롤링
- 데이터불균형
- PCA
- 빅데이터
- 언더샘플링
- 빅데이터분석기사
- 데이터분석전문가
- numpy
- DBSCAN
- LDA
- pandas
- 워드클라우드
- ADsP
- opencv
- 군집화
Archives
Data Science LAB
ImageNet Classification with Deep Convolutional Neural Networks 논문 리뷰 및 정리 본문
📜 논문 review
ImageNet Classification with Deep Convolutional Neural Networks 논문 리뷰 및 정리
ㅅ ㅜ ㅔ ㅇ 2023. 4. 24. 00:33728x90
딥러닝의 기초 논문이라고 할 수 있는 ImageNet Classification with Deep Convolutional Neural Networks (AlexNet) 를 리뷰해 보려고 한다.
Link : https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
0. Abstract
- ImageNet LSVRC-2010 대회에서 120만 개의 고해상도 이미지를 1000개의 다른 클래스로 분류하기 위해 대규모의 심층 컨볼루션 신경망을 훈련시킴
- top1, top5 오류율은 각각 37.5%, 17.0%의 오류율을 달성함 (이전보다 상당히 발전)
- 매우 효율적인 GPU 사용
- 오버 피팅을 방지하기 위해 새로운 방법인 ‘dropout’ 기법 사용
- 5개의 convoloution layer와 3개의 fully connected layer를 사용함
1. Introduction
- 이전까지의 데이터셋은 수 만장 정도로 상대적으로 작았기 때문에 간단한 인식 작업은 잘 수행함(MNIST 데이터셋). 그러나 실제 사물은 이러한 데이터와 다르기 때문에 훨씬 많은 데이터셋이 필요함 → ImageNet이라는 22000 이상의 카테고리의 15만장의 고해상도 이미지 데이터셋 등장
- 대용량의 데이터셋을 처리하기 위해 더 큰 용량의 모델이 필요함
- CNN의 용량은 depth나 breath를 달리하면서 조절함, 훨씬 적은 connection과 파라미터를 사용해 훈련하기 쉽지만, 성능이 나쁠 가능성 존재
- 이 논문의 기여
- ILSVRC-2010 및 ILSVRC-2012 대회에 사용된 ImageNet 데이터셋에서 가장 큰 CNN을 훈련시켰고 최고의 성능을 달성함
- Highly-optimized GPU를 이용한 2D conv의 implementation과 CNN을 학습시키기 위한 operation을 공개함
- 과적합을 방지하기 위해 여러 방법 사용함
- 5개의 conv-layer와 3개의 fc-layer를 사용했는데 conv-layer 중 어떤 layer를 제거해도 성능이 확연히 떨어짐 (모두 유의미한 layer)
2. The Dataset
- ImageNet은 약 22,000개 범주에 속하는 1,500만 개 이상의 레이블이 지정된 고해상도 이미지의 데이터셋
- ILSVRC는 1000개의 범주 각각에 약 1000개의 이미지가 있는 ImageNet의 부분 집합으로 총 약 120만 개의 훈련 이미지, 50,000개의 검증 이미지, 150,000개의 테스트 이미지 데이터셋
- 두 가지 오류율 사용
- top-1
- top-5 : 가장 가능성이 높은 5개의 레이블 중 정답 레이블이 존재할 확률
- ImageNet은 가변해상도 이미지데이터셋으로 256 × 256의 고정 해상도로 다운샘플링 (CenterCrop)
- 각 픽셀을 Centerize 하는 것 외에는 다른 전처리 과정을 진행하지 않음
3. The Architecture
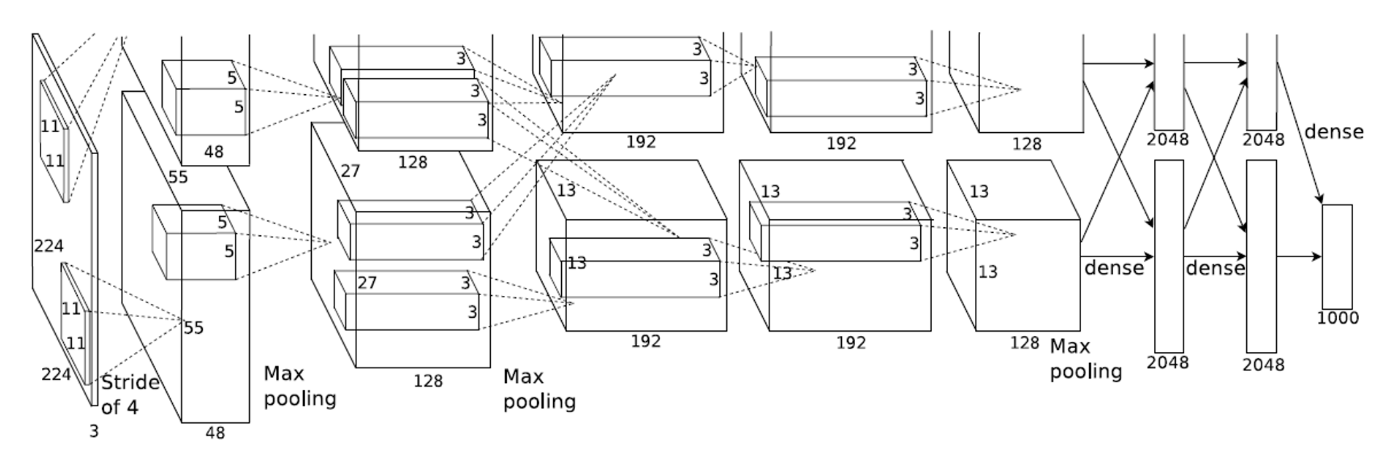
5개의 convolution layer와 3개의 fullt-connected layer로 총 8개의 layer로 구성
3-1. ReLU Nonlinearity
- 보통 뉴런의 출력은 tanh(x) 함수나 sigmoid를 거침 → 이러한 활성 함수는 gradient descent 방법으로 학습할때 학습 속도를 매우 저하시킴
- non-saturating nonlinearity로 ReLU를 사용 (tanh보다 빠름)
- f(x) = max(0,x)
- 아래 그래프를 통해 tanh를 사용했을때 보다 ReLU를 사용했을 때 속도가 훨씬 빠른 것을 알 수 있음
3-2. Training on Multi GPUs
- 하나의 GTX 580 GPU는 메모리가 3GB밖에 되지 않아 네트워크의 학습에 제한이 있기 때문에 두 개의 GPU를 사용하여 학습시킴
- 현재의 GPU는 호스트 시스템 메모리를 거치지 않고 서로의 메모리에서 직접 읽고 쓸 수 있기 때문에 교차 GPU 병렬화에 특히 적합함
- GPU parallelization은 커널을 반으로 나누어 각각 하나의 GPU에 할당하는 건데, 추가로 두 GPU 간의 communication은 특정 layer에서만 발생하도록 함. 따라서 layer 3에서는 layer 2의 모든 kernel map을 받아 올 수 있지만 layer 4는 같은 GPU의 layer 3의 커널 맵에서만 입력을 받음
- 2개의 GPU를 사용하면 1개의 GPU를 사용할 때보다 더 적은 시간을 소요함
3.3 Local Response Normalization
- ReLU는 입력 정규화를 필요로 하지 않음
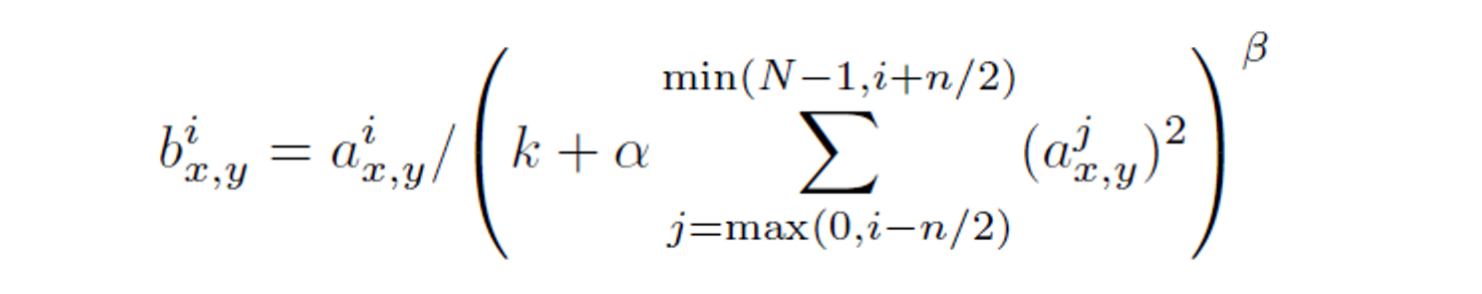
- 합은 동일한 공간 위치에서 n개의 "인접한" 커널 맵에 걸쳐 실행되며, N은 레이어의 총 커널 수
- 커널 맵의 순서는 물론 훈련이 시작되기 전에 임의적으로 결정됨
- response normalization은 lateral inhibition을 구현한 형태로 다른 커널에서 계산된 출력과 경쟁을 일으키는 것
- 상수 k, n, α, β는 hyperparameter로, k = 2, n = 5, α = 10-4, β = 0.75 사용
- 정규화는 top- 1, top- 5의 오류율을 각각 1.4%와 1.2% 감소 시킴
3.4 Overlapping Pooling
- CNN의 Pooling layer는 동일한 커널 맵에서 인접한 뉴런 그룹의 출력을 요약함
- 보통, pooling layer는 overlap하지 않음
- pooling layer의 커널 사이즈를 z, stride를 s라고 할 때, s=z이면 보통의 overlap하지 않는 pooling layer로 해석함
- 그러나 본 논문에서는 z=3, s=2로 하여 overlapping pooling을 구성해 과적합이 덜 발생하게 됨
3.5 Overall Architecture
- CNN의 전반적인 구성은 가중치가 있는 8개의 layer를 포함하는데, 처음 5개는 컨convolution-layer이고 나머지 3개는 fully-connected layer로 구성됨, 마지막 fc layer는 소프트맥스 함수를 사용해 1000개의 레이블에 대한 분포를 생성함
- 2, 4, 5 번째 conv layer의 커널은 동일한 GPU에 상주하는 이전 layer의 커널 맵에만 연결됨
- 3번째 conv layer는 2번째 conv layer의 모든 커널 맵에 연결
- Response-normalization layer는 1번째와 2번째 conv layer 뒤에 위치함
- Max-pooling layer는 1,2,5번째 conv layer뒤에 위치함
- ReLU는 모든 conv layer와 fc layer뒤에 위치함
- 각 layer
- Conv layer1: 224x224x3의 입력 이미지를 11x11x3 크기의 stride가 4인 96개의 커널로 출력
- Conv layer2: conv layer1의 출력을 response-normalize, pooling을 거치고 5x5x48 크기의 256개의 커널로 출력
- Conv layer3: conv layer2의 출력을 ormalize, pooling을 3x3x256 크기의 384개의 커널로 출력
- Conv layer4: conv layer3의 출력을 3x3x192 크기의 384개의 커널로 출력
- Conv layer5: conv layer4의 출력을 3x3x192 크기의 256개의 커널로 출력
- FC layer1: conv layer5의 출력을 pooling을 거치고 4096개로 출력
- FC layer2: fc layer1의 출력을 4096개로 출력
- FC layer3: fc layer2의 출력을 1000개로 출력
4. Reducing Overfitting
neural network는 60만개의 parameter를 가짐 → 과적합 발생 가능
4.1 Data Augmentation
- 데이터 변환을 사용하여 데이터의 수를 인위적으로 증가 시킴
- 두 가지 방법이 존재함 (두 방법 모두 변환된 이미지를 디스크에 저장할 필요 X)
- 이미지 변환과 수평 반사를 생성 : 256x256 이미지를 224x224 크기로 RandomResizedCrop하고 RandomHorizontalFlip을 적용 → 하나의 이미지에서 2048장의 이미지를 얻을 수 있게 됨
- RGB 채널의 강도(intensity)를 바꿈 : pi와 γi는 각각 RGB 픽셀 값의 3×3 공분산 행렬의 고유 벡터와 고유 값이며, αi는 평균이 0이고 표준편차가 0.1인 가우시안에서 추출한 랜덤 변수, 아래 값을 각각 RGB 이미지 픽셀에 더함
- top- 1의 오류율을 1% 이상 줄임
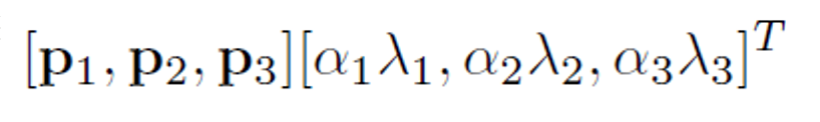
4.2 Dropout
- Droptout 기법은 사용자가 지정한 확률을 근거로 하여 특정 뉴런에 신호를 전달하지 않는 방법
- 확률 0.5의 각 hidden neuren의 출력을 0으로 설정하는 것으로 구성
- 0을 출력한 뉴런은 역전파에 참여하지 않음
- 매번 입력에 따라 활성화되는 뉴런이 달라지고, 이로 인해 뉴런 간의 복잡한 co-adaptation을 줄이게 됨 → 여러 뉴런 간의 조합에서도 확실한 특징만을 학습하게 됨
5. Details of learning

- 배치 크기가 128개, Momentum 0.9, Weight decay: 0.0005인 확률적 경사 하강법을 사용하여 모델을 훈련
- Weight initialization: Gaussian distribution of μ=0, σ=0.01
- Bias initialization: 2,4,5번째 conv layers, fc layers -> 1 / 1,3번째 conv layers -> 0
- learning rate: 0.01
- Epochs: 90
- 아래 식에 의해 weight 갱신
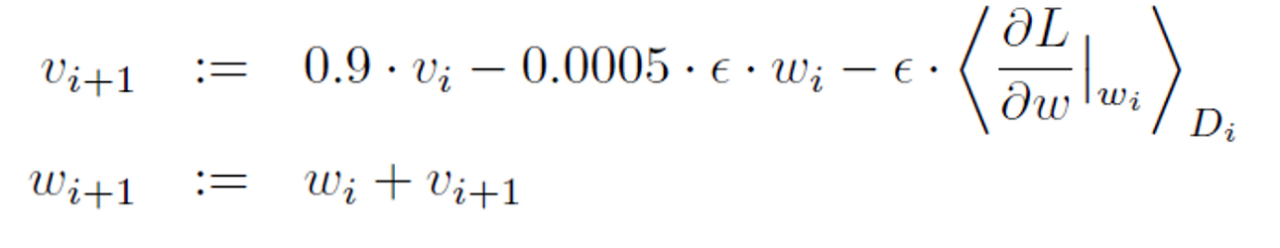
- Bias를 1로 초기화 한 layer는 ReLU에 양수가 들어가게 하여 학습을 가속시킴
- learning rate는 모든 layer에 대해 공통적으로 적용시키지만, 현재 learning rate에서 validation error가 개선되지 않는다면 현재 learning rate에 10을 나눠줌 → 학습 종료까지 3번 감소
6. Results

- 우측의 결과를 확인하면 CNN구조가 다른 구조에 비해 효율적임을 알 수 있음
- 분류를 진행할때 모델 한개가 아닌 여러개의 모델의 평균 출력값을 이용하여 결과를 구하는 방식을 앙상블이라 하며 앙상블 모델을 이용하면 성능이 향상 됨을 좌측 결과에서 확인할 수 있음
- 여러개의 유사한 CNN을 이용하여 1개의 CNN모델만 사용한 것 보다 좋은 결과를 얻는 것을 보여주며 좌측 결과중 1CNN*/7CNN*이라 적힌 부분은 이 전 모델의 학습 가중치인 fine-tune을 초기값으로 제작한 모델이라는 의미이며 처음부터 가중치를 학습시키는것 보다 더 나은 성능을 보여줌
728x90
'📜 논문 review' 카테고리의 다른 글
| Deep Residual Learning for Image Recognition (ResNet) 논문 리뷰 및 정리 (0) | 2023.04.30 |
|---|
'📜 논문 review' Related Articles
more

Comments