
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 텍스트분석
- ADP
- 파이썬
- 오버샘플링
- 빅데이터
- dataframe
- LDA
- PCA
- 데이터불균형
- opencv
- Python
- 데이터분석
- 크롤링
- 대응표본
- 워드클라우드
- 데이터분석전문가
- datascience
- pandas
- ADsP
- DBSCAN
- 군집화
- 언더샘플링
- 빅데이터분석기사
- Lambda
- numpy
- 데이터분석준전문가
- t-test
- 주성분분석
- iloc
- 독립표본
Data Science LAB
[CV] Object Detection 2 Stage Detectors (R-CNN, Fast-RCNN, Faster-RCNN) 정리 본문
[CV] Object Detection 2 Stage Detectors (R-CNN, Fast-RCNN, Faster-RCNN) 정리
ㅅ ㅜ ㅔ ㅇ 2023. 5. 21. 17:00본 포스팅은 Naver Boostcamp AI Tech 5기
Object Detection 강의 자료를 바탕으로 작성되었습니다.
0. Overview
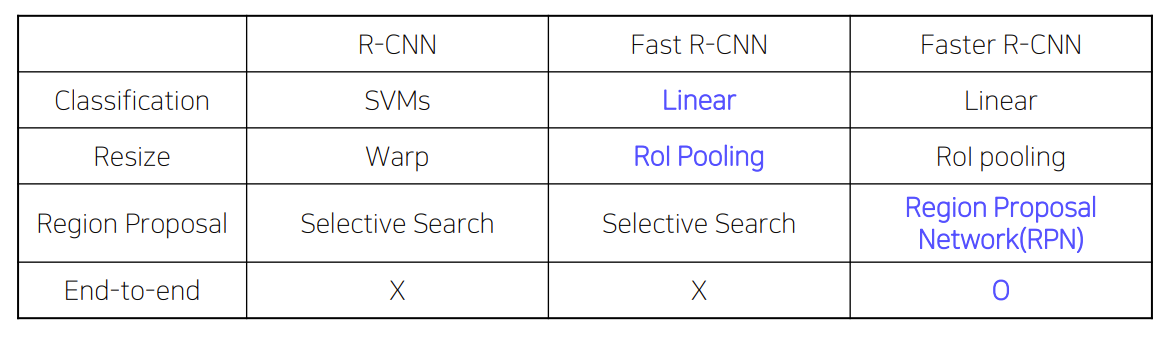
Object Detection은 크게 One-stage Detector과 Two-stage Detector로 분류된다.
Two - Stage Detector은 사람의 객체 인식 방법과 유사하다.


큰 흐름은 객체가 있을 법한 위치 -> 해당 객체가 무엇인지 예측
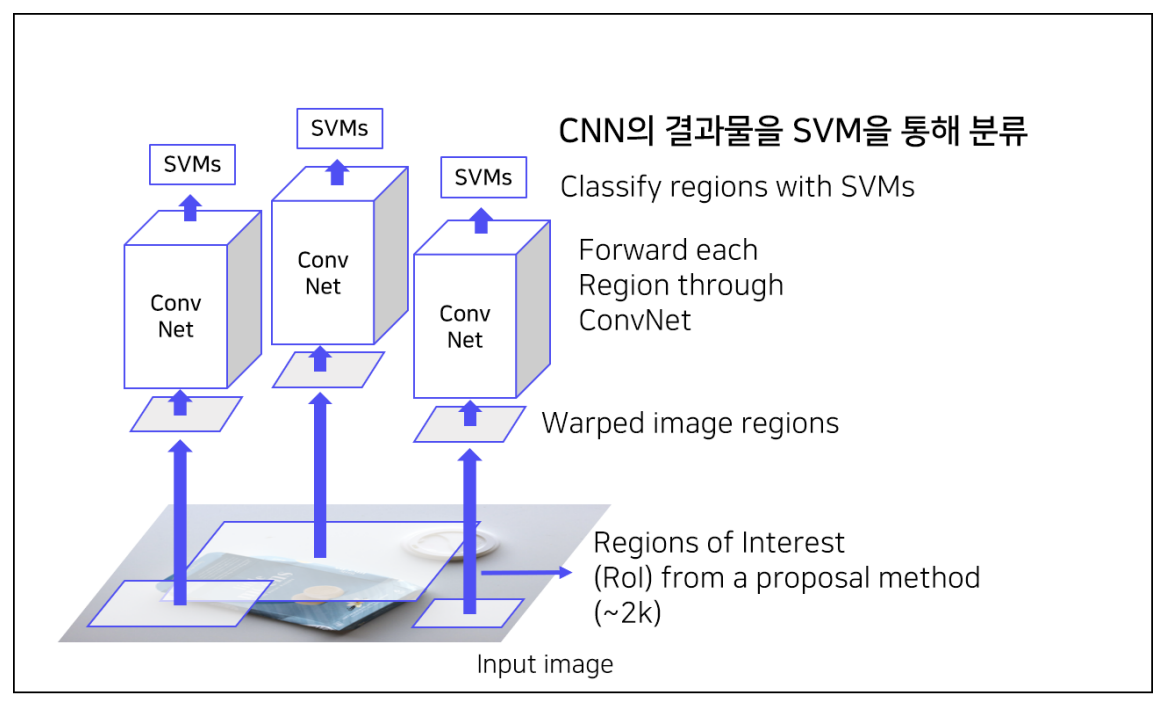
1. R-CNN

Object Detection 분야에 딥러닝을 최초로 적용시킨 모델이며 여러 모델의 기준이 되는 중요한 모델
객체 위치 예측 + 클래스 판별 Process
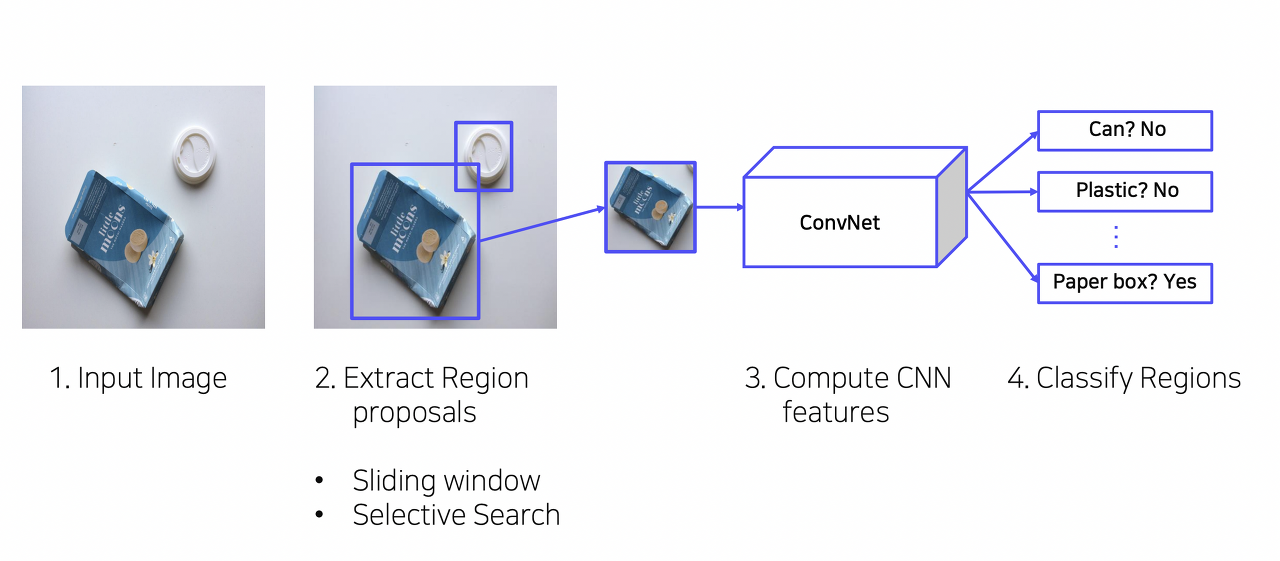
1) 입력이미지 받음
2) Selective Search를 통해 약 2000개의 ROI (Region of interest) 추출

Sliding Window : 다양한 Scale의 무수히 많은 영역 검출 하지만 이미지의 대부분은 배경일 확률이 높기 때문에 Sliding Window기법을 사용하면 객체가 포함될 가능성이 줄어듦, 비효율적
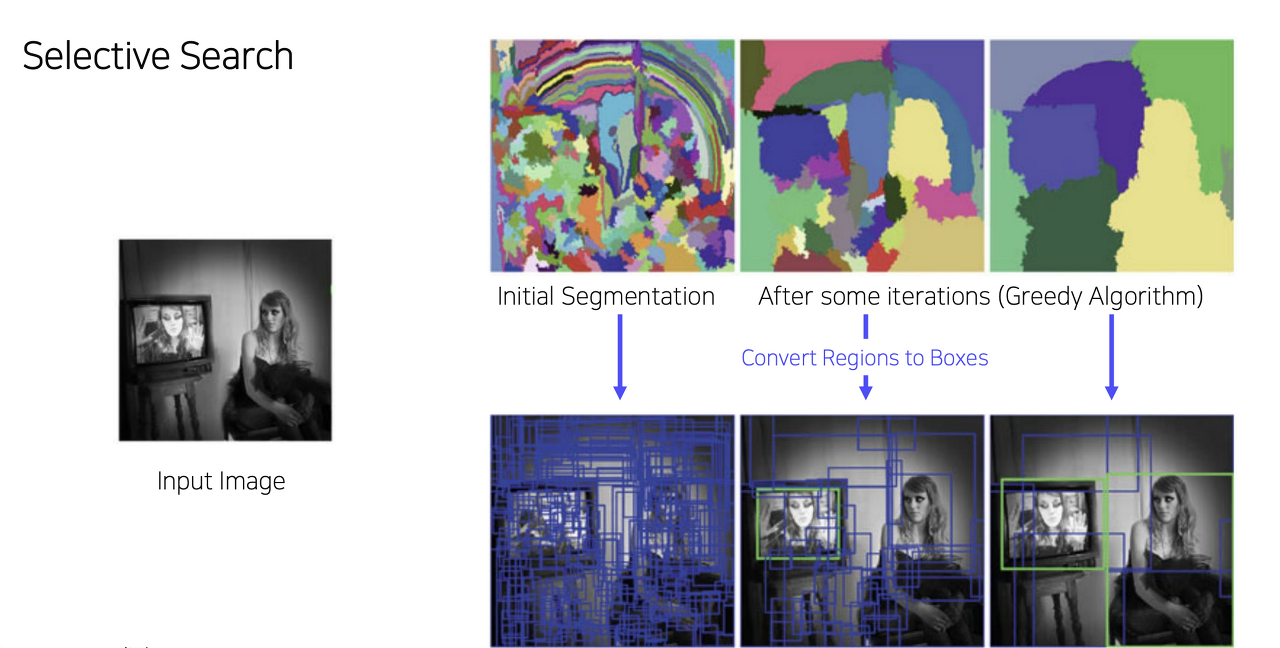
Selective Search : 이미지의 색, 질감, 모양 등 이미지의 특성을 활용해 추출하며 작은영역부터 시작하여 점차 통합하며 덩어리를 선택해 나감 -> R-CNN에 이용됨
3) ROI 영역을 동일한 사이즈로 wrapping
: 마지막 FC layer에서는 고정된 size만을 입력으로 받기 때문에 resize한다.
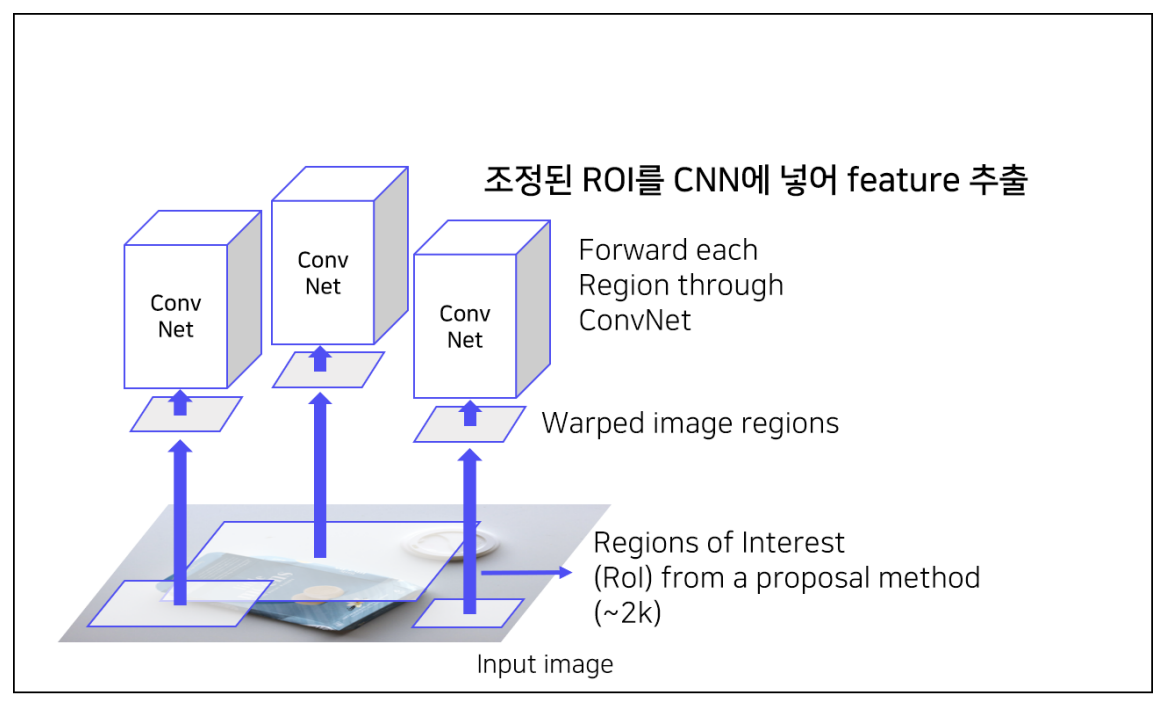
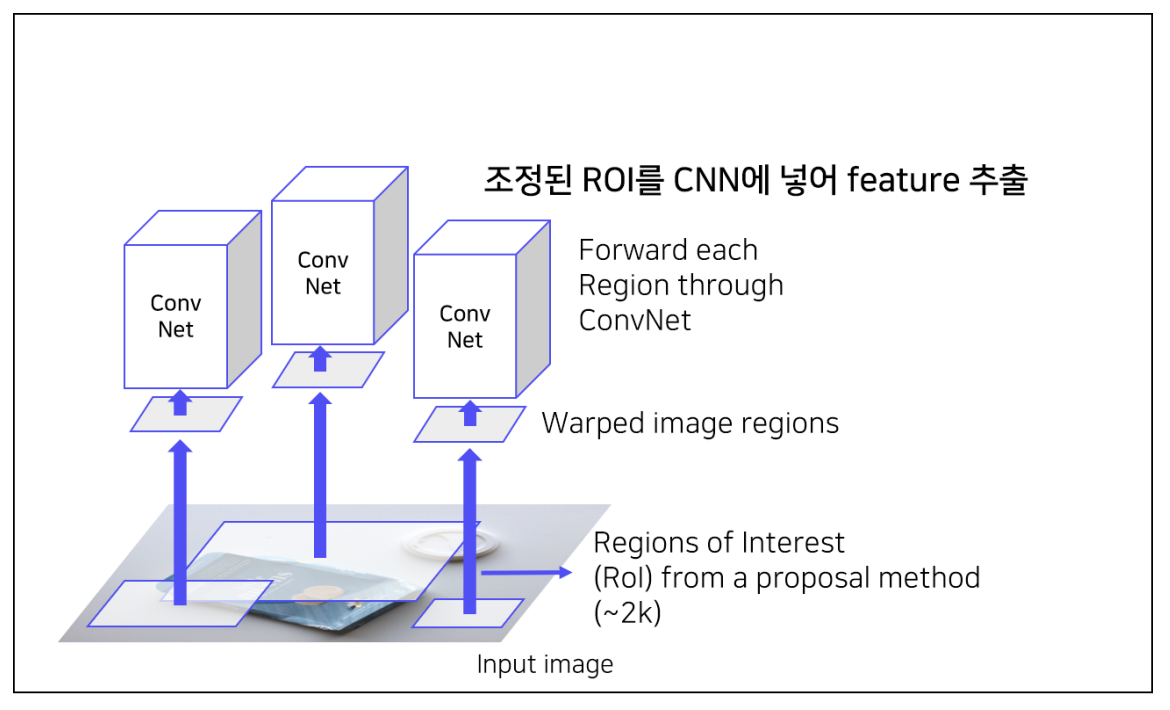
4 ) ROI를 CNN에 넣어 feature 추출
- 각 region 마다 4096-dim feature vector를 추출 -> ROI가 2000개이므로 dim : 2000*4096
- AlexNet 마지막에 FC layer 추가한 과정, 필요에 따라 Fine-tuning
- IOU > 0.5 : Positive / IOU < 0.5 : Negative -> 총 positeve sample 32, negative sample 96으로 구성
5 ) CNN을 통해 나온 Feature를 regression을 통해 bounding box 예측
- 객체가 존재할 법한 위치를 좀 더 정교화
- bounding box의 중심점, w, h를 GT의 중심점 w,h로 옮기는 delta값을 계산함
- Output : Class의 개수 + 1 (Background) 개의 confidence score
Hard negative mining
Hard Negative = False Positive
모델이 객체라고 예측했지만 실제는 배경인 경우를 강제로 다음 배치의 negative sample로 mining하는 기법
큰 비중의 배경 샘플들을 quality 있게 사용하기 위함
Shortcomings
2000개의 region이 각각 CNN 통과 -> 엄청 큰 연산량
강제 wrapping -> 성능 하락의 가능성 (각각 크기가 다를 수 있음)
CNN, SVM classifier, bbox regressor가 각각 따로 학습
End-to-End가 아님 (여러 모델들이 따로따로 있어서)
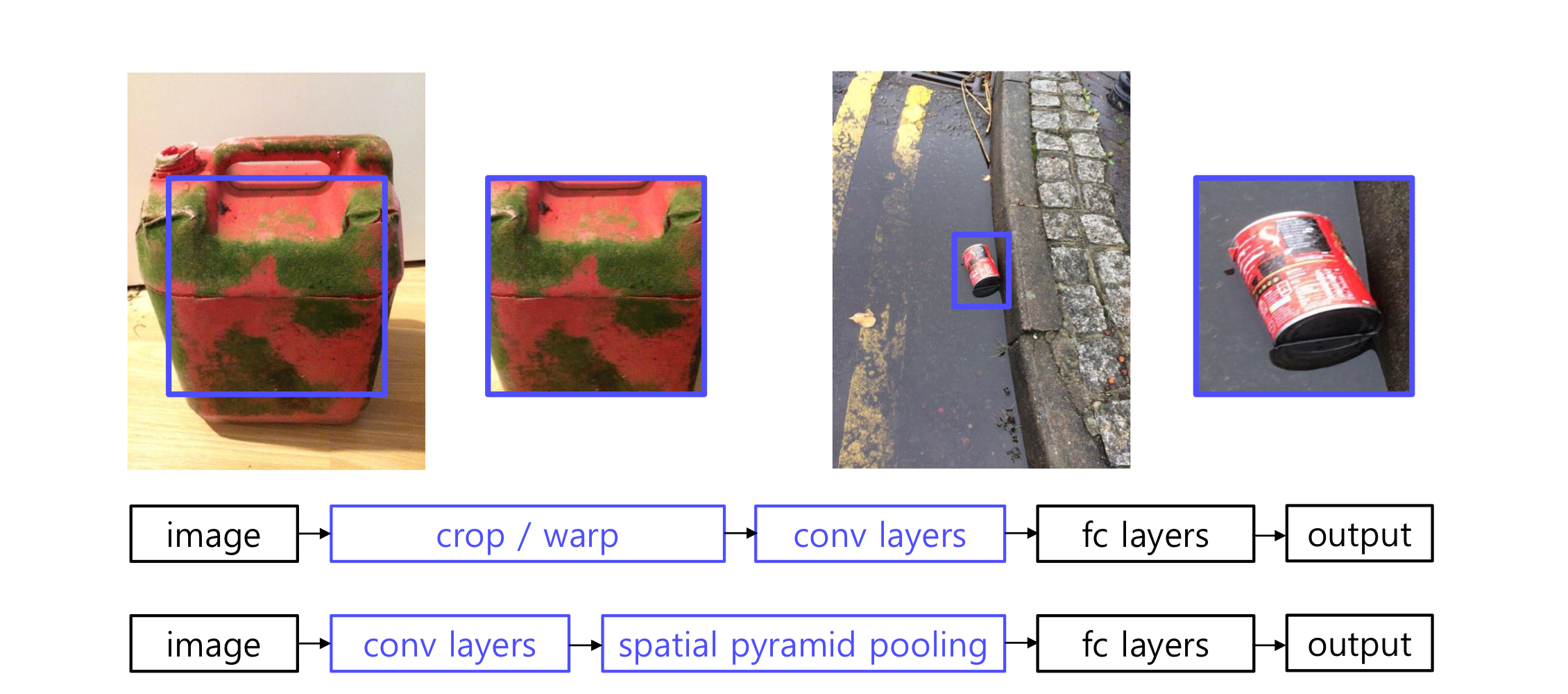
2. SPPNet
: R-CNN의 단점을 Spatial Pyramid Pooling으로 보완
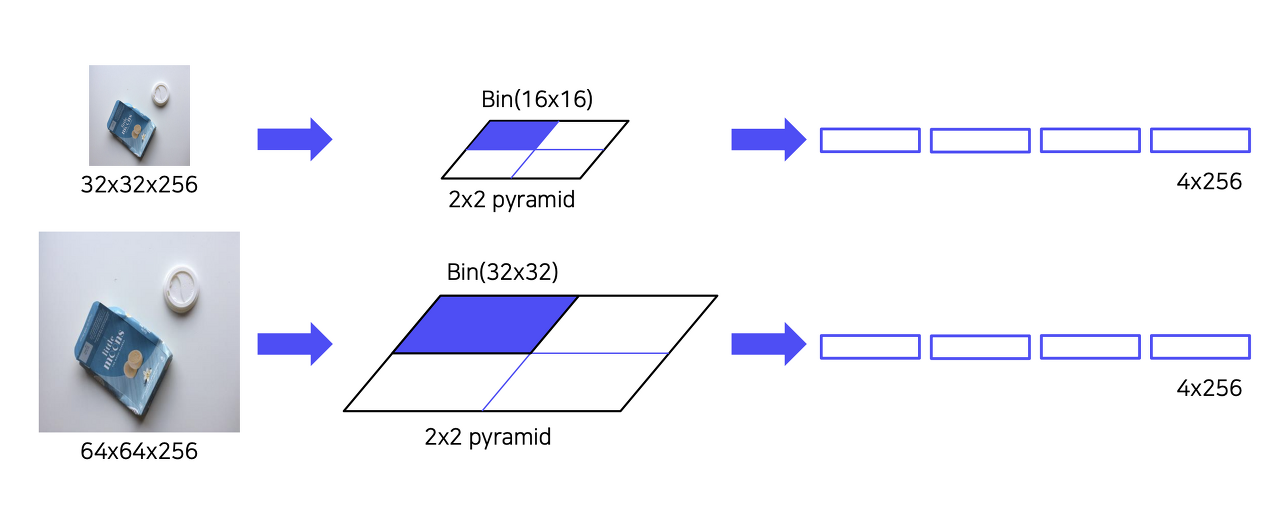
Spatial Pyramid Pooling
- Binning이라고도 불리며 고정된 size의 feature vector를 정해놓고 bin의 크기를 조정하며 Pooling하는 기법
- Pooling 방법과 상관없이 고정된 하나의 Feature를 추출함
Shortcomings
CNN, SVM Classifier, Bounding box regression 따로 학습
End-to-End X
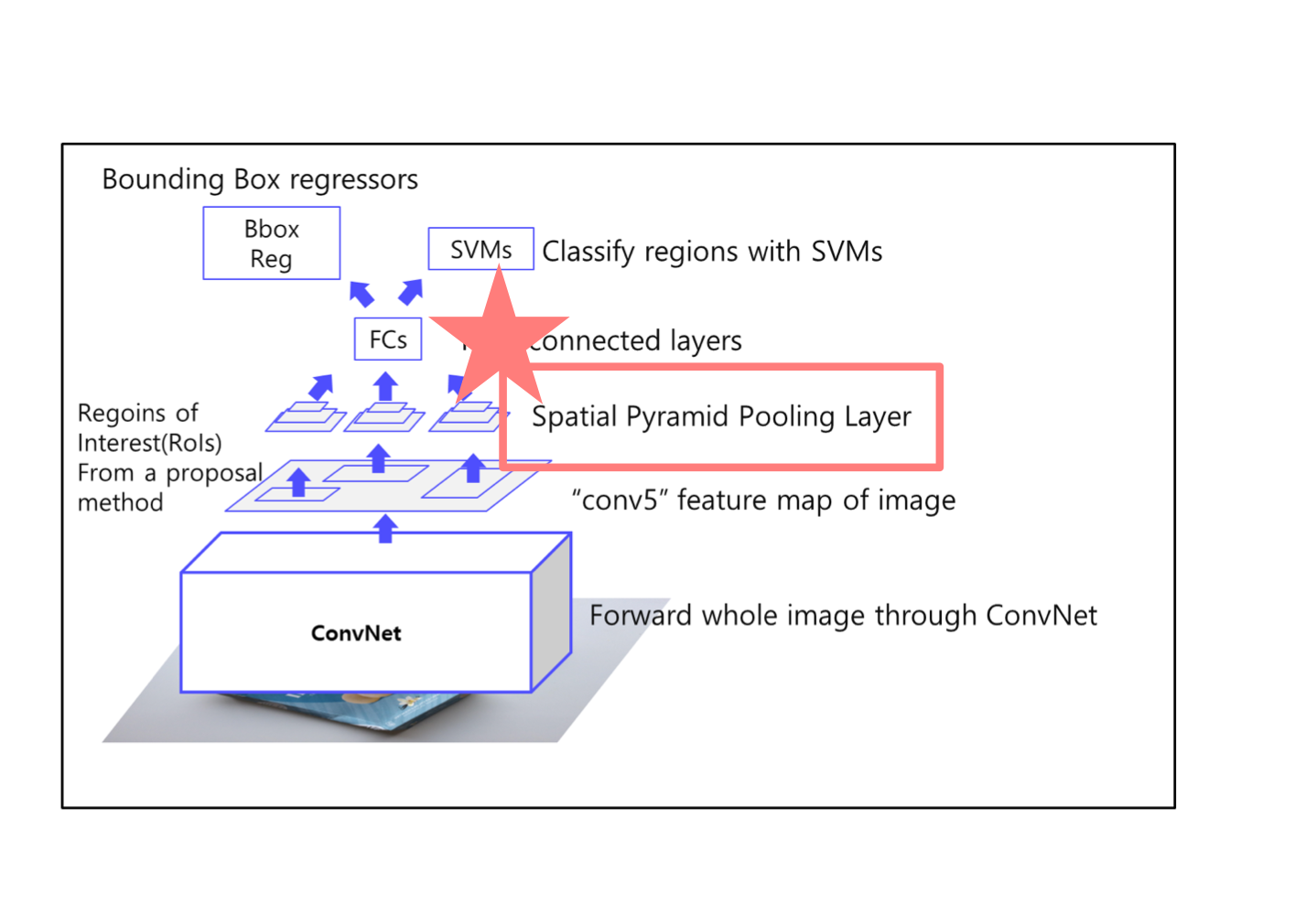
3) Fast R - CNN
: R-CNN 보완
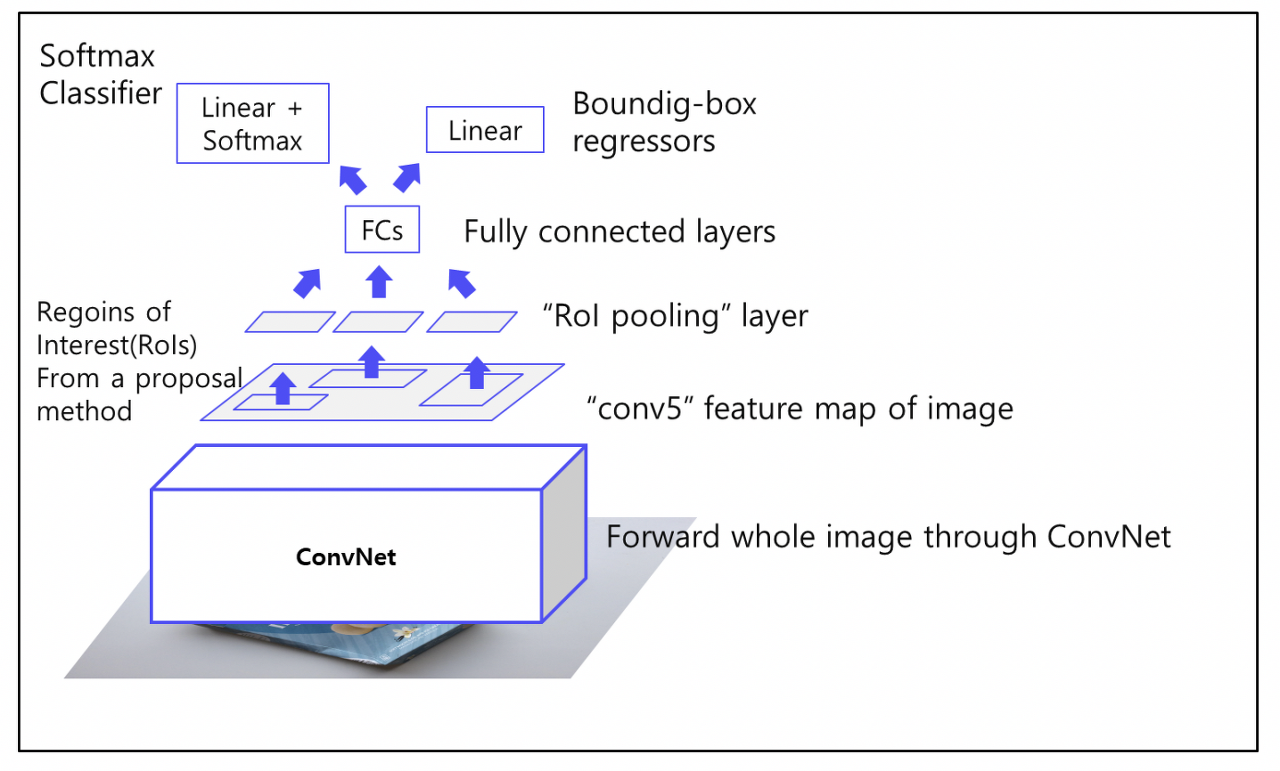
1) ROI Projection, ROI Pooling
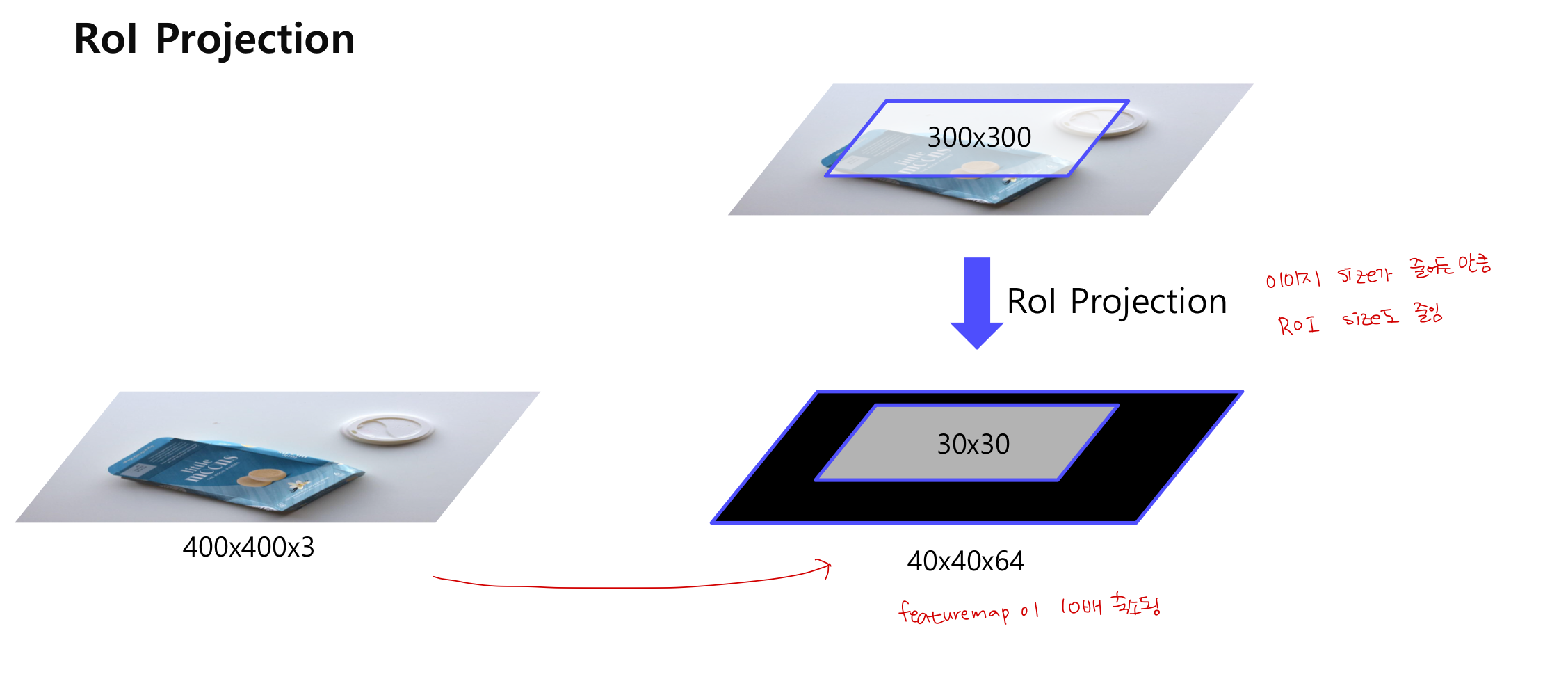
ROI Projection
Selective Search를 통해 2000개의 region 추출 후 CNN을 통과한 feature map에 해당 ROI를 추출함
ROI Proejction을 통해 투영시키면 featuremap이 축소됨 (이미지 size가 줄어든 만큼)
중심점 w, h는 일치함
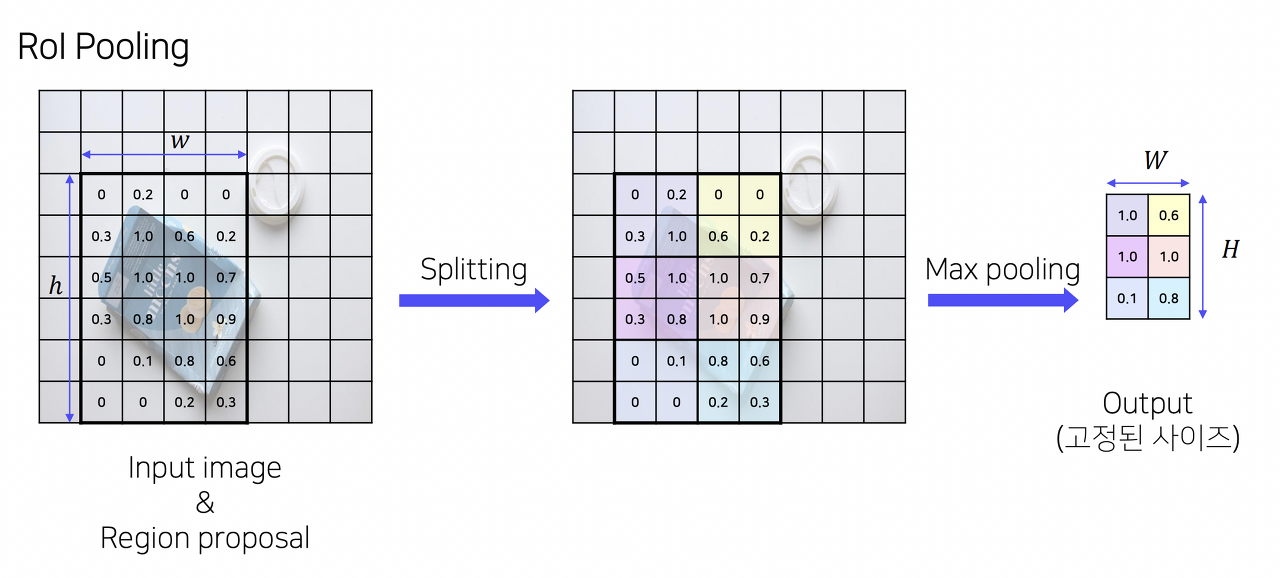
ROI Pooling
고정된 크기의 feature 추출 (고정된 vector를 얻기 위한 과정)
SPP 사용
2) 각 ROI를 Fully Connect에 통과 시킨 후 Softmax Classifier, bbox regressor 통과
- 클래스 개수 : 클래스 (C개) + 배경 (1개)
Hierarchical sampling
R-CNN은 이미지에 존재하는 ROI를 모두 저장해 사용 -> 한 배치에 서로 다른 이미지의 ROI 포함
Fast R-CNN은 한 배치에 한 이미지의 ROI만을 포함 -> 한 배치에서 연산과 메모리 공유 가능
-> 여전히 End to End 모델은 아님
Selective Search를 통해 region을 추출하기 때문에 학습 가능한 알고리즘이 아닌 CPU 내에서 학습하는 알고리즘
4. Faster R-CNN
: Selective search + RPN
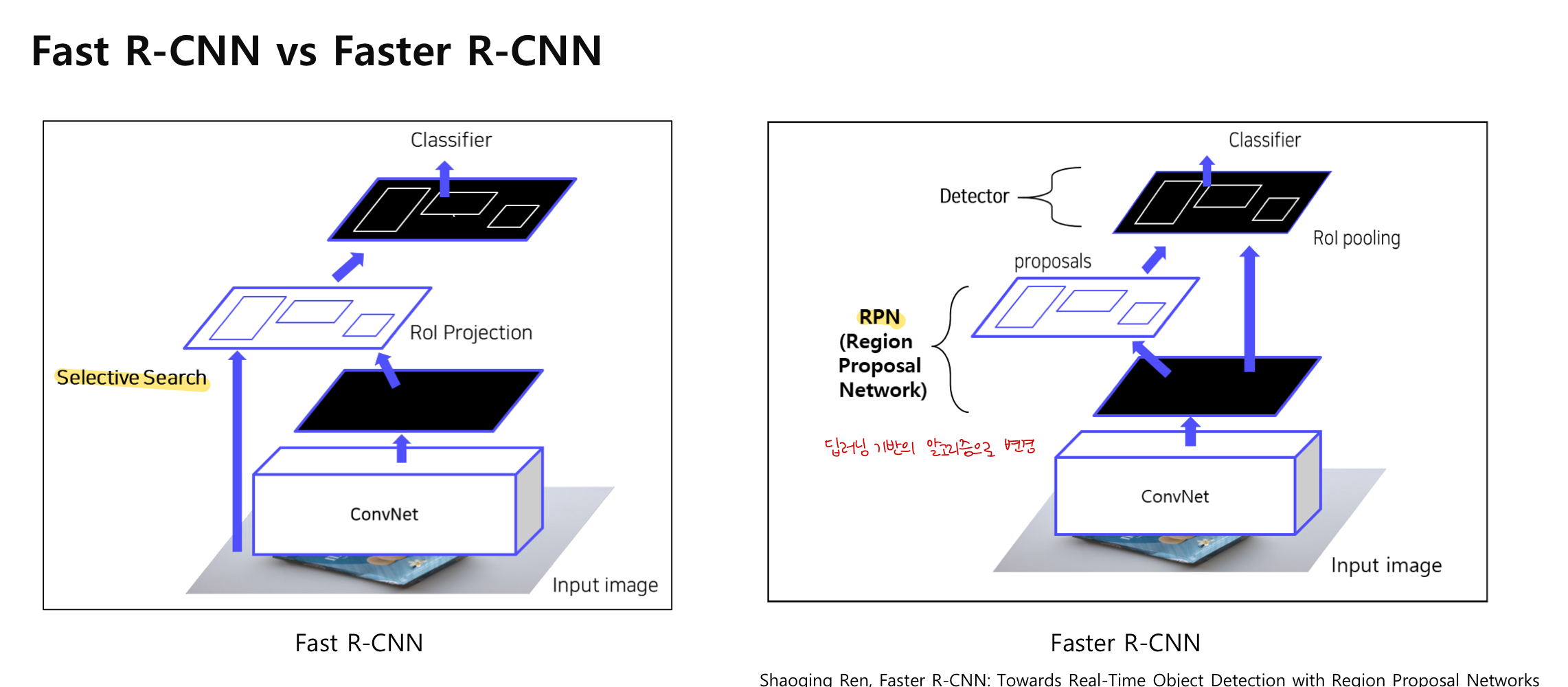
Fast R-CNN의 단점인 Region Rroposal을 개선하고자 selective search를 사용하지 않고, 딥러닝 기반인 RPN으로 ROI를 계산함 -> GPU를 통한 연산 가능
1) 이미지를 CNN에 넣어 feature maps 추출 (CNN 한 번만 사용)
2) RPN을 통해 RoI 계산
Anchor Box
: feature map 사이즈가 고정된다는 문제점을 해결하기 위함
1. 각 셀 마다 비율, scale을 다르게 해 N개의 anchor box 생성 (객체 크기 고려)
2. anchor box에 객체가 포함되었는지 미세 조정 -> RPN으로 판단

RPN
RPN은 단순히 물체가 있을법한 위치를 proposal하는 목적으로 사용되기 때문에 전체 클래스의 결과가 아닌 물체가 있는 지 없는지에 대한 여부만 출력함
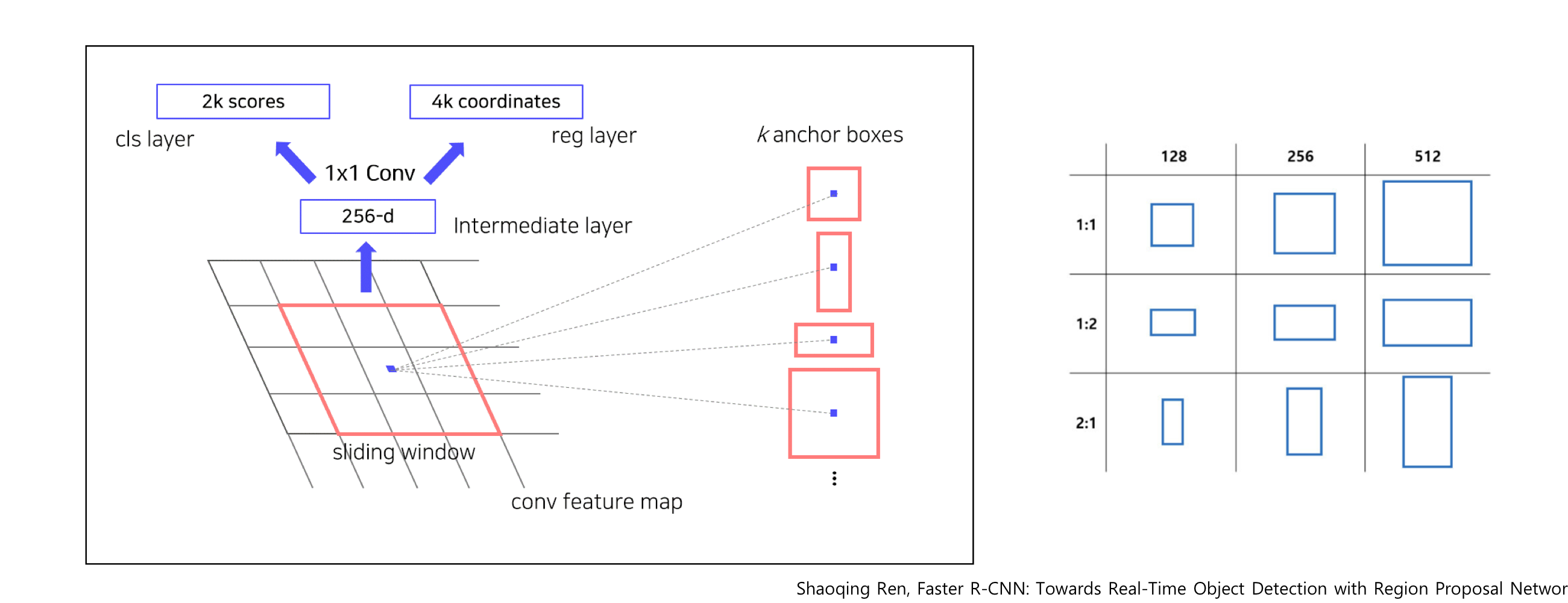
1. 크기에 상관없이 백본 모델(CNN)에서 나온 feature map을 입력으로 받음
2. 3*3 conv 연산을 통해 intermediate feature를 생성
3. 1*1 conv 연산을 통해 binary classification 수행 (9개의 anchor box 각각에 수행함) -> 즉 연산량은 2*9
4. 1*1 conv 연산을 통해 bounding box regression 수행 (9개의 anchor box 각각에 수행함) -> 즉 연산량은 4 (bounding box) * 9
5. 즉, 각 anchor box에 대해 score가 나오게 되는데, 이 score가 높으면 box가 객체를 포함하고 있을 확률이 높음
6. Score 가 높은 Top N개의 anchor box 선택
7. 선택된 box를 어떻게 조절할 지 coordinates를 적용해 w, h, x, y가 변형되어 나오게 됨
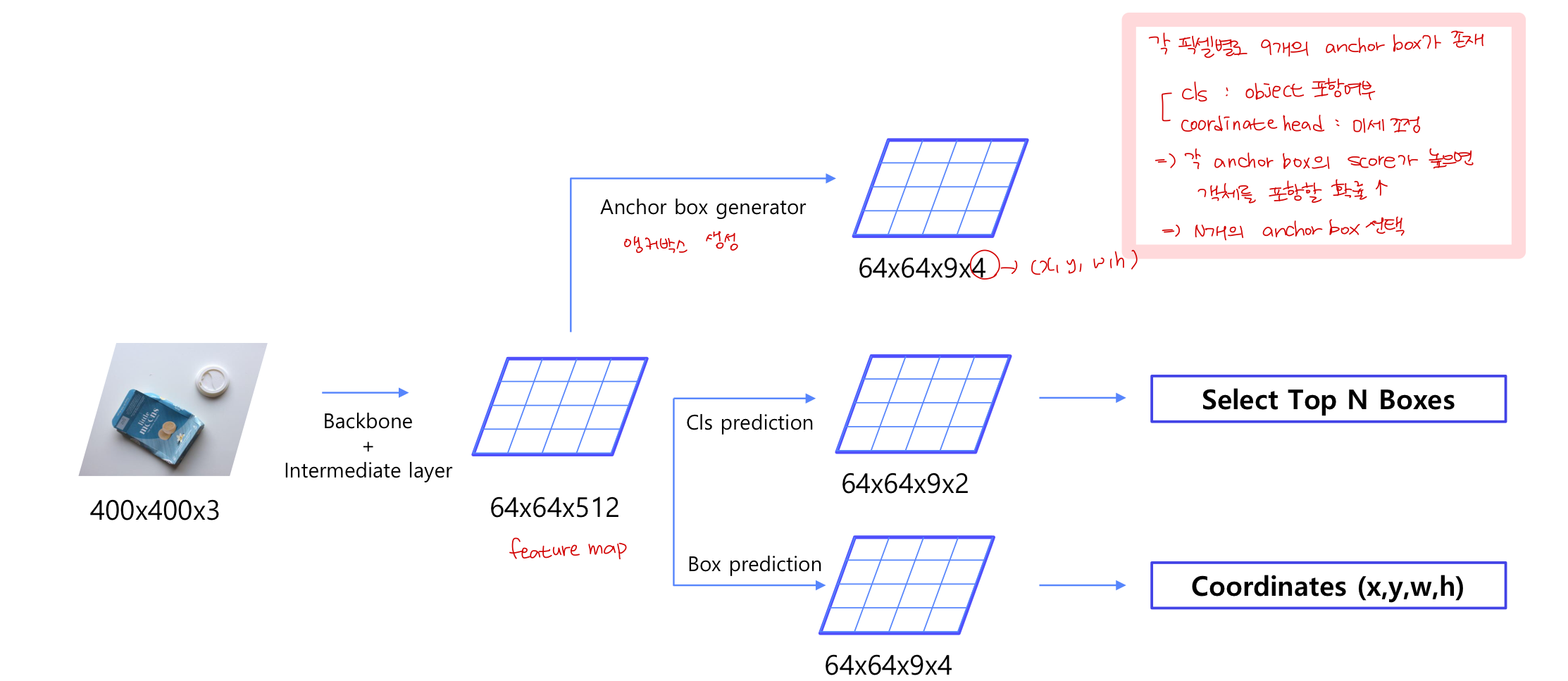
NMS
RPN의 과정으로 유사한 RPN proposals를 제거하기 위해 사용됨
class score를 기준으로 proposal을 분류함
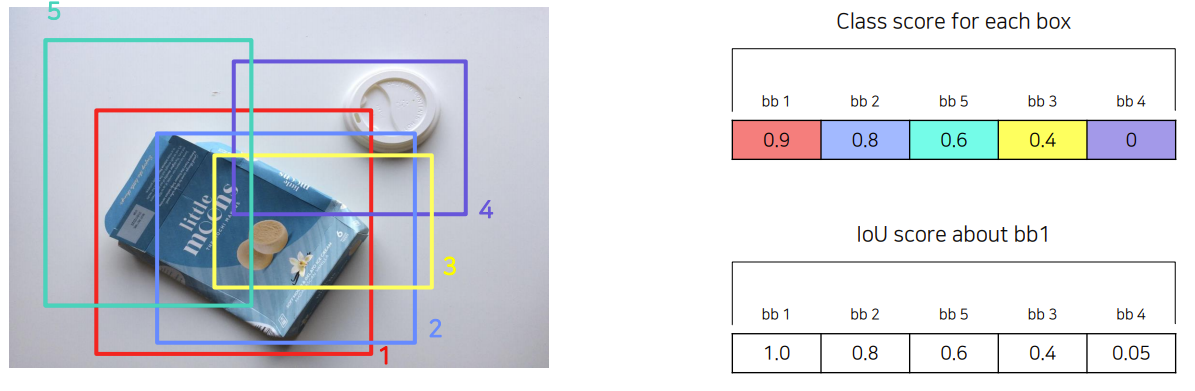
1. 각 box score 정렬
2. bb1과 겹치는 비율 계산 후 정렬
3. IoU가 0.7 이상인 (겹치는 부분) 영역들은 중복된 영역으로 판단하고 제거함
4. 최종적으로 1000~2000개의 ROI가 나오게 수행
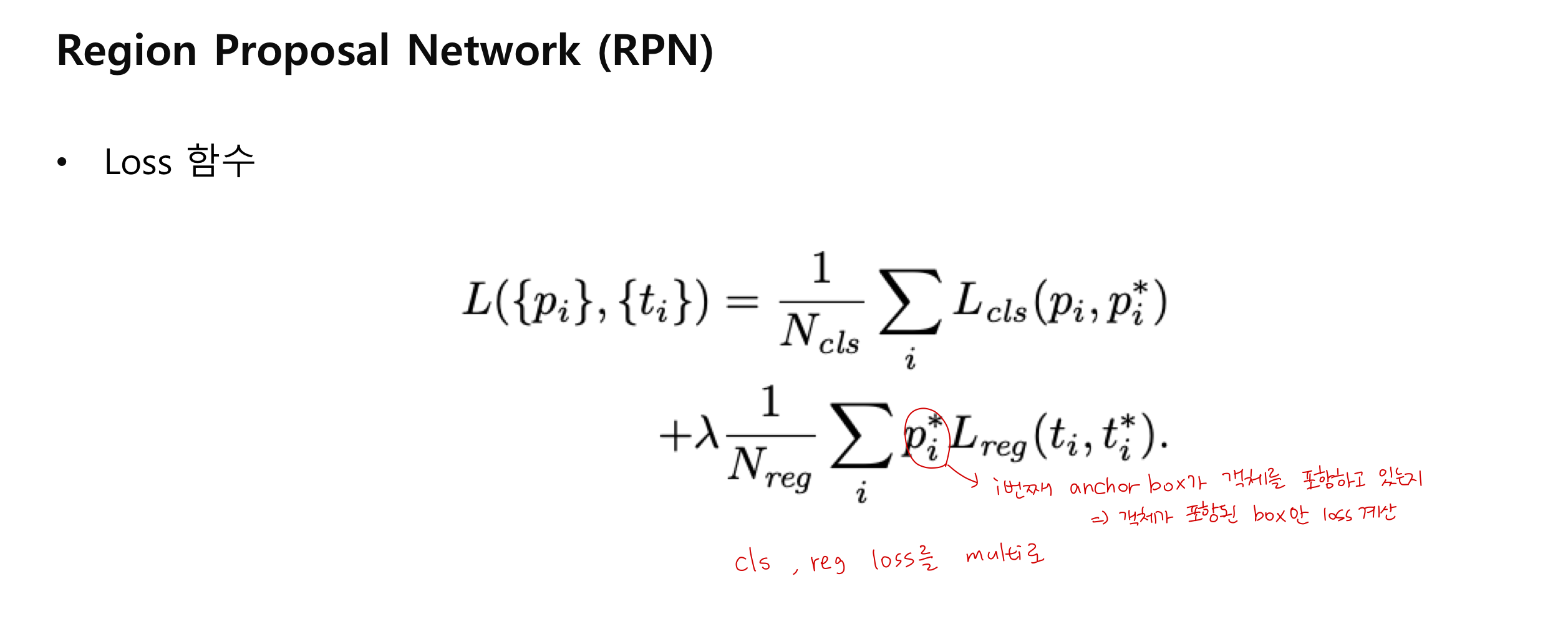
RPN 단계에서 classification과 regressor 학습을 위해 앵커박스를 positive/negative sample들로 구분함
- IoU > 0.7 : GT (32개)
- IoU < 0.3 : negative sample (background) (96개)
- 그외 나머지 : 학습데이터로 사용 X
Loss 함수 계산
Training 방법
1. Imagenet pretrained backbone load + RPN 학습
2. Imagenet pretrained backbone load + RPN from step 1 + Fast RCNN 학습
3. Step 2 finetuned backbone load & freeze + RPN 학습
4. Step 2 finetuned backbone load & freeze + RPN from step 3 + Fast RCNN 학습
-> 학습 방법이 복잡하기 때문에 최근에는 Approximate Joint Training을 활용함
'🖥️ Computer Vision > Object Detection' 카테고리의 다른 글
| [CV] Object Detection library (1) - Detectron 2 (0) | 2023.05.28 |
|---|---|
| [CV] Object Detection 1stage detectors (0) | 2023.05.22 |
| [CV] Object Detection Neck 정리 (0) | 2023.05.21 |
| [CV] Object Detection Overview (evaluation 방법) (0) | 2023.05.18 |



