
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ADP
- DBSCAN
- numpy
- iloc
- 오버샘플링
- 워드클라우드
- 크롤링
- opencv
- 주성분분석
- 파이썬
- 데이터분석전문가
- pandas
- 텍스트분석
- Python
- datascience
- 데이터분석준전문가
- LDA
- 군집화
- 언더샘플링
- t-test
- 독립표본
- 데이터불균형
- 빅데이터분석기사
- Lambda
- 빅데이터
- ADsP
- 데이터분석
- dataframe
- PCA
- 대응표본
Data Science LAB
[Python] KMeans Clustering(K-평균 군집화) 본문
KMeans Clustering이란?
가장 자주 사용되는 군집화 알고리즘으로, 데이터셋을 K개의 군집으로 군집화하는 알고리즘이다.
임의의 군집 중심점 개수(K)를 설정하여 해당 중심에 가장 가까운 데이터를 선택한다. 군집 중심점은 선택된 데이터의 평균 지점으로 이동하고, 이동된 중심점에서 다시 가까운 포인트를 선택, 다시 중심점을 평균 지점으로 이동하는 프로세스를 반복적으로 수행한다. 더이상 중심점의 이동이 없을 때까지 반복을 계속한다.
KMeans Process
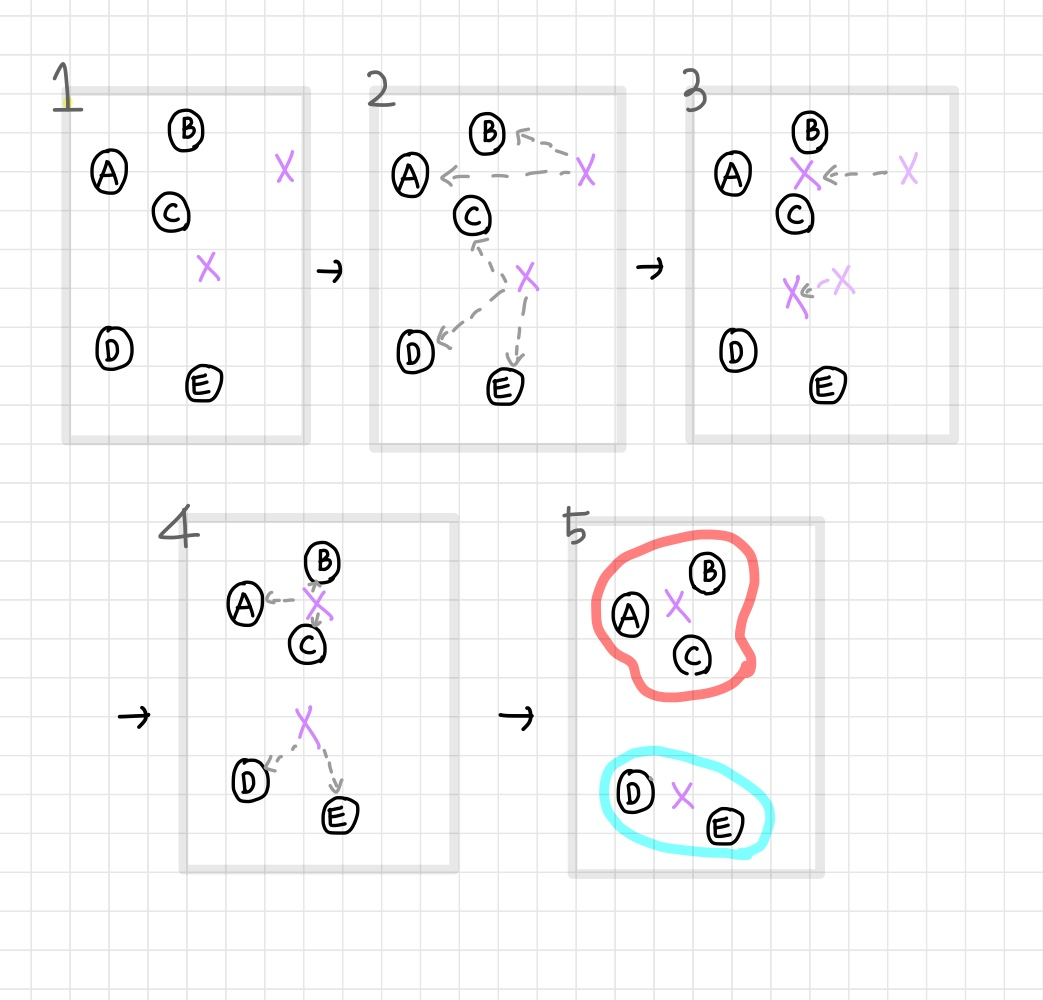
1. 군집화의 기준이 되는 중심을 구성하려는 군집의 개수만큼 임의의 위치에 가져다 놓음
2. 각 데이터는 가장 가까운 곳에 위치한 중심점에 소속
3. 각 데이터의 소속이 결정되면 군집 중심점을 소속된 데이터의 평균 중심으로 이동
4. 바뀐 중심점의 위치에 맞춰 소속 변경
5. 다시 중심점을 소속된 데이터의 평균 중심으로 이동
6. 소속 변경이 없을 때까지 반복하고 종료
KMeans 장점
1. 가장 많이 활용되는 알고리즘으로 쉽고 간결
2. 비지도 학습이기 때문에 데이터에 대한 사전 학습이 필요하지 않음
KMeans 단점
1. 거리기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화 정확도가 떨어짐(PCA 차원감소 적용으로 해결)
2. 반복 횟수가 많으면 수행 시간이 매우 느려짐
3. 군집의 개수(K)를 결정하기 어려움
KMeans Parameter
사이킷런 패키지의 KMeans 클래스는 다음과 같은 파라미터를 가지고 있다.
| Parameter | default | 설명 |
| n_clusters | 군집화할 개수(중심점의 개수,k) | |
| init | k-means++ | 초기 군집 중심점의 좌표 설정 방식 |
| n_init | 10 | 초기 군집 중심점 몇 번 설정 |
| max_iter | 최대 반복 횟수, 이 횟수 이전에 모든 데이터 이동이 끝나면 종료 | |
| algorithm | 'auto' | auto, full, elkan |
KMeans 알고리즘을 이용한 iris 데이터 셋 군집화
필요 모듈과 데이터셋 로드
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
df = pd.DataFrame(data = iris.data, columns =['sepal_length','sepal_width','petal_length','petal_width'])
df.head()
사이킷런의 load_iris()를 이용하여 붓꽃 데이터를 추출하고, DataFrame형식으로 변경하여 데이터 핸들링을 편하게 할 수 있다.
3개의 그룹으로 군집화
kmeans = KMeans(n_clusters=3,init = 'k-means++',max_iter=300,random_state = 0)
kmeans.fit(df)
print(kmeans.labels_)
k=3, 최대 반복 회수는 3000으로 설정하고 각 데이터가 어떤 군집으로 분류되었는지 출력해 보았다.
label 값이 0,1,2로 구성되어 있으며 각각 첫 번째, 두 번째, 세 번째 군집에 속하는 것을 의미한다.
df['target'] = iris.target
df['cluster'] = kmeans.labels_
iris_result = df.groupby(['target','cluster'])['sepal_length'].count()
print(iris_result)
분류 타깃이 0인 데이터들은 모두 1번 군집으로 잘 그룹화되었지만, 타깃 1과 2는 분산되어서 군집화 되었음을 확인할 수 있었다.
시각화
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_transformed=pca.fit_transform(iris.data)
df['pca_x'] = pca_transformed[:,0]
df['pca_y'] = pca_transformed[:,1]
df.head()
2차원 평면상에 개별 데이터의 군집화를 시각적으로 표현하기 위해
속성이 4개인 데이터 셋을 2개로 차원 축소하였다.
X,y 좌표로 개별 데이터를 표현할 수 있게 되었다.
#군집 값이 0,1,2인 경우마다 별도의 인덱스로 추출
marker0 = df[df['cluster'] == 0].index
marker1 = df[df['cluster'] == 1].index
marker2 = df[df['cluster'] == 2].index
#군집 값 0,1,2에 해당하는 인덱스로 각 군집 레벨의 pca_x, pca_y값 추출.o,s,^로 마커 표시
plt.scatter(x=df.loc[marker0,'pca_x'],y=df.loc[marker0,'pca_y'],marker='o')
plt.scatter(x=df.loc[marker1,'pca_x'],y=df.loc[marker1,'pca_y'],marker='s')
plt.scatter(x=df.loc[marker2,'pca_x'],y=df.loc[marker2,'pca_y'],marker='^')
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.title("3 clusters visulaization by 2 PCA Components")
plt.show()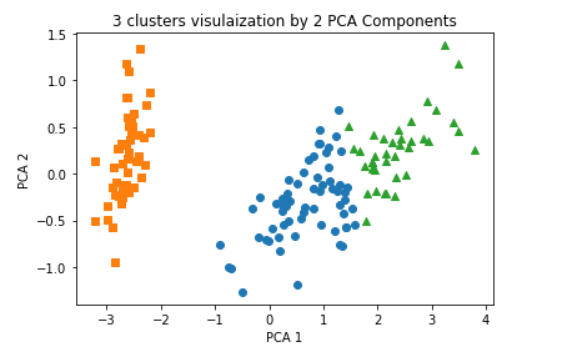
군집값에 따라 마커 표시를 다르게 하여 시각화하였다.
군집화 알고리즘 테스트를 위한 데이터 생성
사이킷런은 다양한 군집화 알고리즘을 테스트하기 위해 간단한 데이터 생성기를 제공한다.
대표적인 군집화용 데이터 생성기로는 make_blobs()와 make_classification() API가 있다.
두 API는 비슷하게 여러 클래스에 해당하는 데이터 셋을 만든다.
make_blobs()는 개별 군집의 중심점과 표준 편차 제어 기능이 추가되어 있고,
make_classification()은 노이즈를 포함한 데이터를 만드는 데에 유용하게 사용할 수 있다.
데이터셋 생성
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
%matplotlib inline
X,y = make_blobs(n_samples=200, n_features = 2, centers=3, cluster_std = 0.8, random_state=0)
print(X.shape,y.shape)
#y target의 분포 확인
unique, counts =np.unique(y,return_counts=True)
print(unique,counts)

생성할 데이터수는 200, 데이터의 피처 개수는 2, 중심점은 3, 표준편차는 0.8로 설정하여 데이터셋을 생성하였다.
피처 데이터셋 X에는 200개의 레코드와 2개의 피처,
타깃 데이터셋 y에는 200개의 레코드가 존재한다.
3개의 cluster 값은 [0,1,2] 이며 각각 [67,67,66]개로 균일하게 구성되어있는 것을 확인 할 수 있다.
데이터를 데이터프레임으로 변환
import pandas as pd
cluster = pd.DataFrame(data=X,columns=['ftr1','ftr2'])
cluster['target'] = y
cluster.head()
데이터셋이 어떤 군집화 분포를 가지고 만들어졌는지 확인
target_list = np.unique(y)
#각 타깃별 산점도의 마커값
markers = ['o','s','^','P','D','H','X']
#3개의 군집 영역으로 구분한 데이터 셋을 생성했으므로 target_list는 [0,1,2]
for target in target_list:
target_cluster = cluster[cluster['target'] == target]
plt.scatter(x=target_cluster['ftr1'],y = target_cluster['ftr2'],edgecolor='k',marker=markers[target])
plt.show()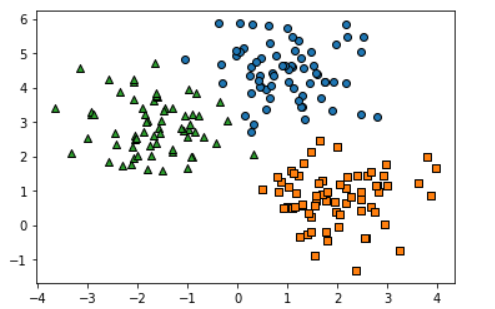
KMeans 군집화 후 시각화
#KMeans 클러스터링 수행
kmeans = KMeans(n_clusters=3,init='k-means++',max_iter=200,random_state=0)
cluster_labels = kmeans.fit_predict(X)
cluster['kmeans_label'] = cluster_labels
#cluster_centers_는 개별 클러스터의 중심 위치 좌표 시각화를 위해 추출
centers = kmeans.cluster_centers_
unique_labels = np.unique(cluster_labels)
#군집화된 label 유형별로 iteration하면서 marker 별 scatter plot 수행
for label in unique_labels:
label_cluster = cluster[cluster['kmeans_label'] == label]
center_x_y = centers[label]
plt.scatter(x=label_cluster['ftr1'],y=label_cluster['ftr2'],edgecolor='k',marker=markers[label])
#군집별 중심위치 좌표 시각화
plt.scatter(x=center_x_y[0],y = center_x_y[1], s=200, color='white',alpha=0.9,edgecolor='k',marker=markers[label])
plt.scatter(x=center_x_y[0],y = center_x_y[1], s=70, color='k',edgecolor='k',marker='$%d$' % label)
plt.show()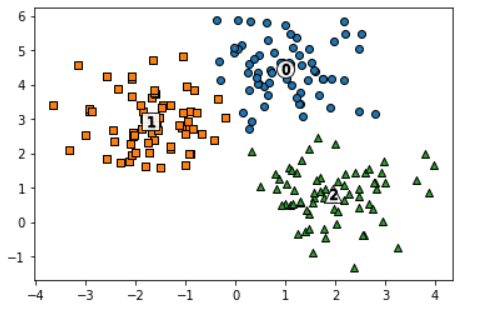
mable_blobs()의 타깃과 kmeans_label은 군집 번호를 의미하므로 서로 다른 값으로 매핑될 수 있다.
print(cluster.groupby('target')['kmeans_label'].value_counts())
'🛠 Machine Learning > Clustering' 카테고리의 다른 글
| [Python] DBSCAN (0) | 2022.03.04 |
|---|---|
| [python] GMM(Gaussian Mixture Model) (0) | 2022.03.03 |
| [Python] 평균 이동 (0) | 2022.03.02 |
| [Python] 군집 평가(실루엣 계수) (0) | 2022.03.01 |



